
編集日
2024年5月
カテゴリ
評価/運用
はじめに
ホールドアウト法は AI モデルの精度を適切に判断するためのデータ分割手法です。この記事では分割後の各データの役割、データ分割の比率、時系列データを分割する際の注意点を解説します。
ホールドアウト法
機械学習モデル開発の目的は未知のデータに対して高い精度を出せるモデルを開発することです。
まだ見ぬデータに対する良し悪しをどうやって判断すれば良いでしょうか?
最も一般的な方法はホールドアウト法(Hold-out Method)と呼ばれる既存のデータを訓練データ、検証データ、テストデータの 3 つに分ける方法です。

分け方に決まったルールはありませんが
- 訓練データ:60%
- 検証データ:20%
- テストデータ:20%
のように訓練データに 60% ~ 80%程割くことが多いです。
訓練データと検証データの分け方を複数パターン試すクロスバリデーション(cross validation)と呼ばれる手法もありますが、ここでは単純なホールドアウト法について解説します。
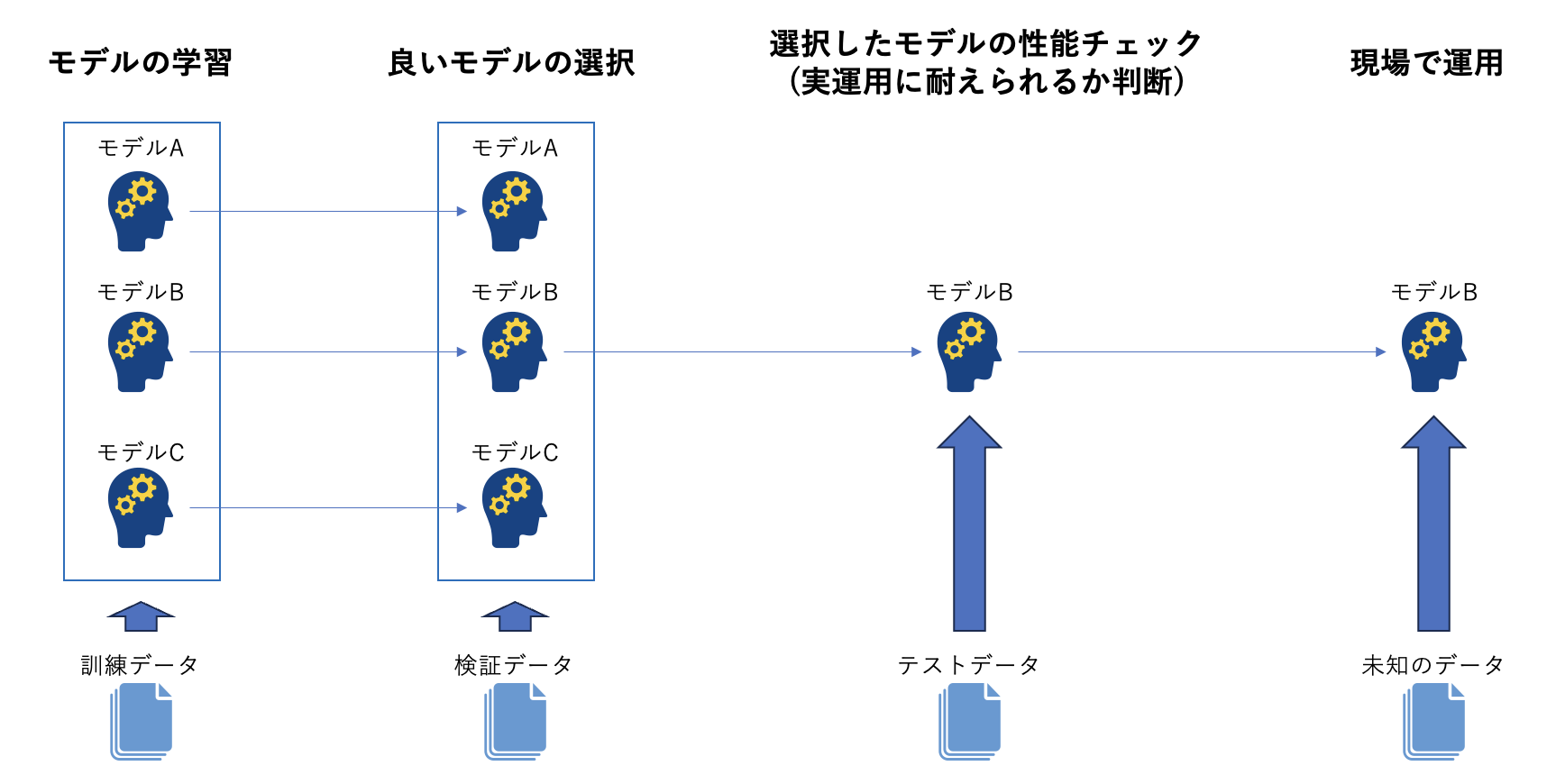
各データの役割
各データの役割を一言で述べると以下のようになります。
- 訓練データ
- モデル学習に用いるデータ
- 検証データ
- 訓練データを使って学習したモデルの中で最も良いモデルを選択するために用いるデータ
- テストデータ
- 検証データを使って選択したモデルが未知のデータに対してどのくらい精度が出せるか(実運用に耐えられるか)を測るために用いるデータ
なぜこれらのデータを別々にする必要があるのでしょうか?
訓練データを検証データを分けずに同じデータを使った場合を考えてみます。
これは学習に用いたデータで性能を測っているので、大学受験生に例えると、一度解いた参考書の問題で学力を測っているようなものです。
これでは正確に学力を測る事ができません。
更に、モデルによっては(パラメータ次第では)訓練データの丸暗記をして、訓練データに対してほぼ誤差 0 の予測を出す事もできてしまいます。(MLP が訓練データの丸暗記をできてしまう特徴の事を万能近似性能といいます。)
このようなモデルに対して訓練データに対する精度からモデルの性能等を調べることはほとんど不可能です。
同じ理由で訓練データとテストデータも別々にする必要があります。
そのため訓練データと検証データ、テストデータは分ける必要があります。
次に検証データとテストデータを分けずに同じデータを使った場合を考えてみます。
学習データと検証データが同じだったときとは違い、学習に使っていないデータで性能を測っているので問題無さそうにも見えますが、実際に現場で使えるかを考えると、選ばれたモデルが偶然良い結果を出しただけという可能性を排除できません。
機械学習モデル開発の目的は「未知のデータに対して高い精度を出せるモデルを開発すること」なので、モデルの学習や選択に一切使ってないデータを使って精度を測らないと現場で使えるかの判断はできません。
よって検証データとテストデータも分ける必要があり、データを 3 つに分割する必要があるのです。
データ分割の比率
訓練データ、検証データ、テストデータの分割は
- 訓練データ:60%
- 検証データ:20%
- テストデータ:20%
のように訓練データの比率が大きくなるように分割する事が一般的です。
訓練データの割合を多くする理由の 1 つは、訓練データの割合が大きい方が実際に現場導入した際の状況に近い検証ができるからです。
ここで機械学習プロジェクトにおけるデータの使い方について少し補足します。
前節の説明では省略しましたが、現場に機械学習モデルを実装する際は既存のデータ全てを使ってモデルの学習をする場合が多いです。
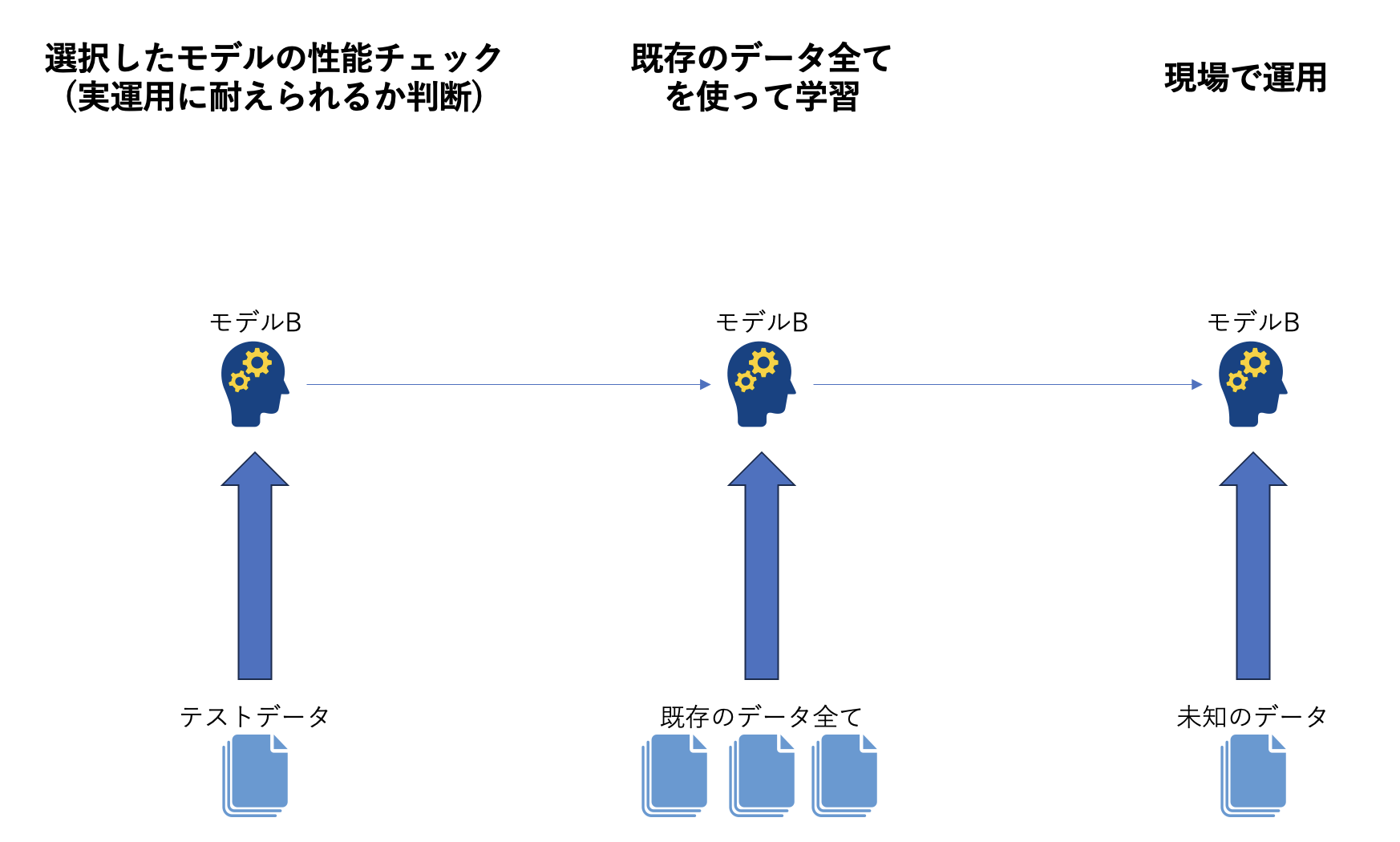
検証に依って良いモデル(良いアルゴリズム)を選択できたのなら、学習データは基本的に多ければ多いほど良いので、全てのデータ使って学習し直すのです。
つまり機械学習モデル開発の検証で興味があるのは「既存のデータ全てを使って学習したモデルが未知のデータに対して出せる精度」なのです。
これに近い状況を再現するために、モデルの学習には既存のデータの多くを使って、検証及びテストのために一部を分けておくというやり方をします。
時系列データを分割する際の注意点
訓練データ、検証データ、テストデータの分割を上手く行わないとリークと呼ばれる現象が起きる事があります。
リークとは実際には使えないデータを検証時に使ってしまう事です。
リークは時系列データでなくても発生しますが、時系列データの場合は特に注意が必要です。
例えば、以下のように訓練データの中に検証データよりも過去のデータと未来のデータが両方入っていたとします。

このような場合、「検証データの予測値は、訓練データの中に入っている過去の実測値と未来の実測値の中間ではないか」といった予測ができてしまいます。
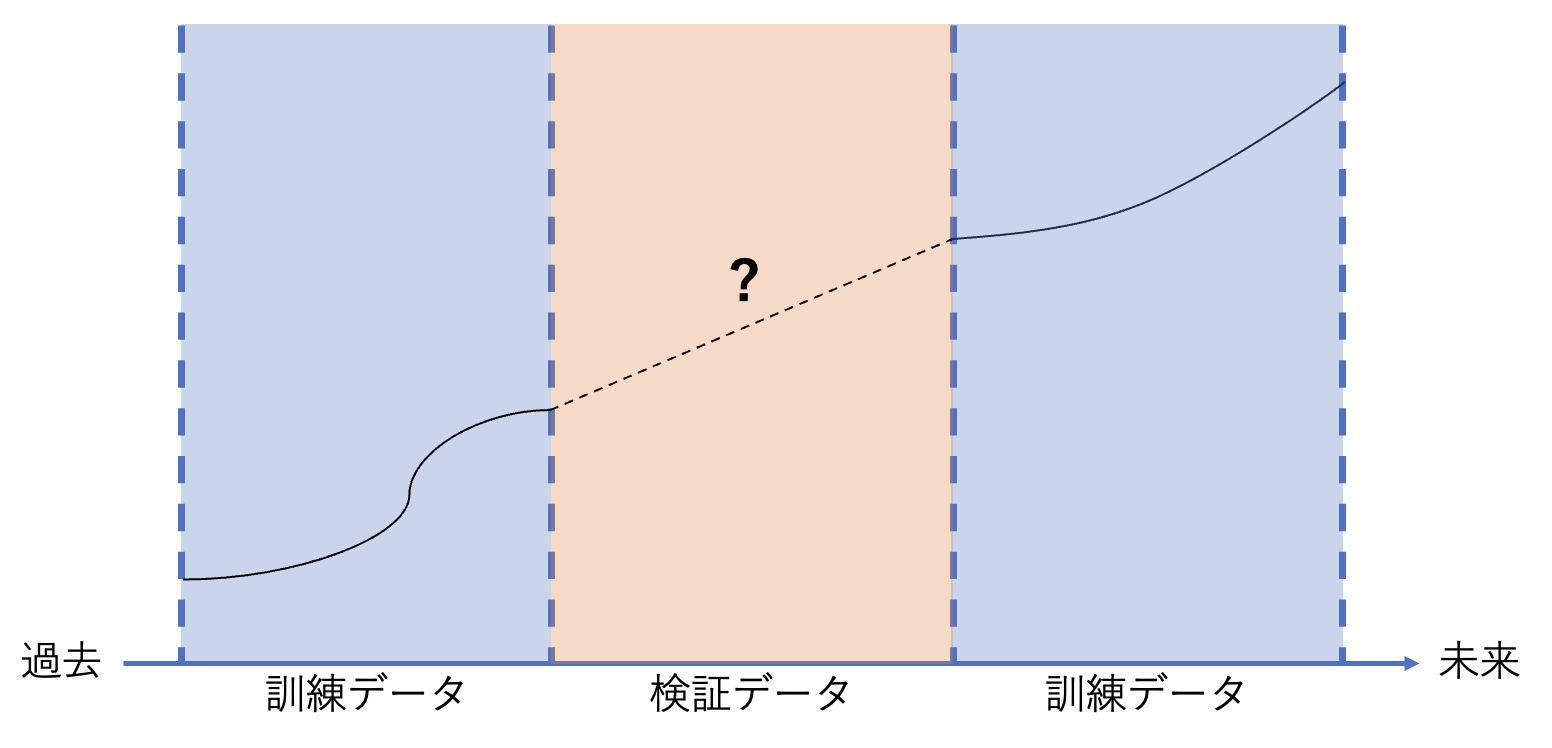
時系列データを使った未来予測の場合、実際に現場で使う際はこのような予測はできません。
このようなリークを避けるために訓練データ、検証データ、テストデータを時系列順になるように分割するのが一般的な方法です。

訓練データと検証データの時系列順を保ったままクロスバリデーションを行うウォークフォワードバリデーション(Walk Forward Validation)という手法もあります。