
編集日
2024年5月
カテゴリ
モデリング/学習
はじめに
時系列分析には時間依存性やトレンド成分、周期成分といった要素しばしばがあり、時系列ではないテーブルデータの分析とは異なる手法が必要となります。
モデルの選択においてもこういった要素が重要となるため、モデルの特徴を理解し、分析対象のデータに合っているか判断しなければなりません。
時系列分析で使われる数理モデルの概要
ここでは時系列分析で良く用いられる数理モデルの紹介をします。
実際に AI モデル開発を行う際は、学習済みモデルを評価するためのベースラインモデルも作成しますが、ベースラインモデル作成の考え方は数理モデル学習の考え方と異なるため、ここでは数理モデルに限って解説をします。
線形回帰モデル
線形回帰はデータ間の関係を線形方程式で(直線で)近似するモデルです。例えば、最小二乗法, LASSO 回帰, RIDGE 回帰, Elastic Net などがあります。
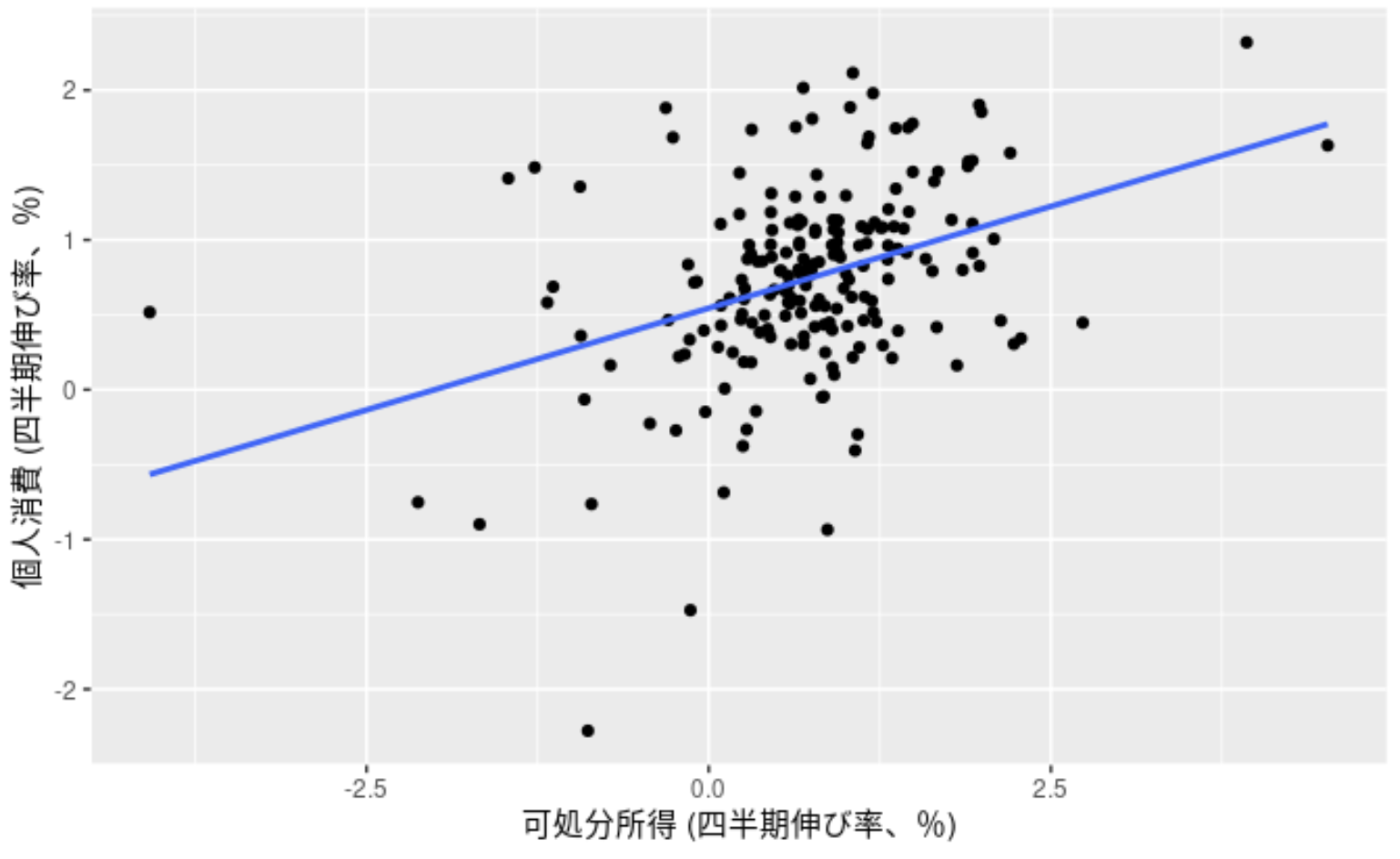
(引用:予測: 原理と実践:線形回帰モデル)
上図は時系列データではありませんが、可処分所得(x 軸)を説明変数、個人消費(y 軸)を目的変数として近似したグラフです。
線形回帰は比較的シンプルなモデルなので、過学習が起きにくいという利点がある一方で、データ間の関係性が線形でなければそもそも近似がうまくいかないという欠点もあります。
また、説明変数に相関係数の高い 2 つ以上のデータが含まれている場合に多重共線性という現象が発生し精度が悪くなる事があります。
過学習や多重共線性の抑制について、詳しくは以下の記事をご覧ください
ごちきか:スパースモデリング(基本編)
ごちきか:次元削減
ごちきか:多重共線性に対応した回帰モデル
自己回帰モデル
自己回帰モデルは目的変数の過去の値を使って予測をするモデルです。例えば、AR, ARIMA, Prophet などがあります。
モデルに依って様々な特徴を持っていますが、比較的新しいモデルである Prophet では目的変数の持つトレンドや周期性を抽出して予測に利用できます。

(引用:PROPHET: Quick Start)
上図はデータから抽出したトレンド成分、1 週間の周期性、1 年間の周期性を表しています。
このようなモデルは長期的なトレンドや強い周期性をもつデータに対して力を発揮します。
決定木回帰モデル
決定木回帰モデルは説明変数の値によってデータを分類し、分類された各クラス(葉)に対して割り当てられた重みを返すモデルです。例えば、Decision tree, Random Forest, XGBoost, LightGBM などがあります。

(引用:XGBoost: A Scalable Tree Boosting System)
上図では、2 つの木が存在し、それぞれの木の葉の値の合計を返すモデルを表しています。
決定木回帰モデルでは説明変数間のスケールに差があっても学習/予測に影響せず、欠損値があっても基本的にそのまま学習/予測が行えるため手軽に扱えるという利点があります。
非線形な関係があっても学習でき、多くの問題に対応できるため機械学習コンペティションを開催しているkaggleではLightGBMという決定木回帰モデルが非常に良く使われています。
一方で、学習データが少ない場合は過学習が起きやすかったり、時系列データのトレンド成分や周期成分を上手く捉えられないという欠点もあります。(これらの欠点はハイパーパラメータ調整や特徴量作成によって対処できる場合もあります。参照:Forecasting with Decision Trees and Random Forests)
ニューラルネットワーク
ニューラルネットワーク(Multi-layer Perceptron (MLP)とも呼ばれる)は人間の脳の構造(ニューロンなど)を模して作られたモデルで、ニューロンの繋ぎ方などを変える事で様々なカスタマイズが可能です。例えば、全結合, RNN, LSTM, 1D-CNN などがあります。

(引用:scikit learn: 1.17. Neural network models)
上図は中間層が 1 つの全結合ニューラルネットワークを表しています。
カスタマイズ性が高く様々な分野に応用されていますが、時系列分析で使われるモデルには単純な全結合ニューラルネットワークや、過去のデータを保持しながら再起的に予測できる Recurrent Neural Network (RNN)、RNN を改良した Long Short Term Memory (LSTM)、時系列データを 1 次元の画像とみなして予測をする 1D convolutional neural networks (1D-CNN)があります。
適切なモデル選択
未来の動向を予測するためには、様々な種類の AI モデルが利用されます。データに適したモデルを選択することは、予測の精度向上に欠かせない要素です。 ここでは機械学習を用いた数理モデルのこと全般を AI モデルと呼ぶことにします。 これらのモデルは、入力されたデータから法則性やパターンを学習し、それに基づいて予測値などのアウトプットを生成する仕組みをもっています。
各モデルの理解を深めることで、扱っているデータに最適な AI モデルを選ぶことが可能となり、より正確な未来の予測をすることが可能です。
有効な場面(線形回帰モデル編)
線形回帰モデルは、その解釈のしやすさから多くの場面で重宝されます。このモデルは、説明変数と目的変数の関係が直線的であると仮定しますが、 現実のデータは常にこの仮定に従うわけではありません。 また、現場で扱う多くのデータは非線形な関係にあることが多いため、線形モデルでは適切な予測が困難な場合があります。
それでも、線形モデルは以下のような場面で有効です。
- 例えば
- 解釈のしやすさ : 線形モデルは数式が単純で理解しやすい。各特徴量の影響を把握しやすく、モデルの予測に対する説明が求められる場合に重要
- 初期段階のモデリング : データに明らかな非線形関係がない場合や、初期段階でのモデル構築には、線形モデルが効率的。複雑なモデルへ移行する前のベースラインとしても有効
- 計算効率 : 線形モデルは計算コストが低い。大規模データセットに対しても比較的早く学習できる
- 注意点
- 非線形関係の扱い : データに非線形のパターンが存在する場合、線形モデルでは適切な予測が困難。例えば、非線形モデルや特徴量の変換を検討する必要あり
- 多次元データの正則化 : 多くの特徴量を含むデータに対しては正則化手法を適用し、過剰適合を防ぐことが重要。モデルの複雑さを制御し、汎化性能を高める(※)
※Ridge、Lasso、および ElasticNet は、機械学習において一般的に使用される正則化手法です。 これらの手法を適用することで、学習データに過剰適合することを防ぎ、より汎化性能が高い AI モデルを構築することが可能になります。各正則化手法については以下を参照してください。
- Ridge
- メリット:L2 正則化を用いて過剰適合を抑制。すべての特徴量をモデルに保持しながらも、過剰適合のリスクを軽減。特に、多くの特徴量が相関している場合に有効
- デメリット:パラメータの値を完全にゼロにはしないためモデルが複雑。モデルの解釈性は低下する可能性がある
- 選定方法:AI モデルにおいて過剰適合している場合。また、すべての特徴量を維持したい場合
- Lasso
- メリット:L1 正則化を用いて不要な特徴量の係数をゼロに減少させる。モデルが自動的に特徴選択を行い、より単純で解釈しやすいモデルが生成される
- デメリット:一部の重要でない特徴量が完全に除外される可能性があり、重要な情報の損失につながる場合がある。また、多数の特徴量がある場合、パフォーマンスが低下する可能性がある
- 選定方法:モデルの解釈性を高めたい場合。または不要な特徴量を取り除いて単純なモデルを作成したい場合。特に、多くの特徴量が存在するがその中で重要なものが限られている場合に効果的
- ElasticNet
- メリット:Ridge と Lasso の両方の特徴を兼ね備えいて、多くの特徴量が相関している場合の過剰適合を抑制しつつ、不要な特徴量を除外することが可能
- デメリット:パラメータのチューニングが複雑になりがち。Ridge や Lasso に比べて計算コストが高くなる可能性がある。また、適切な正則化のバランスを見つけるのが難しい場合がある
- 選定方法:過剰適合を抑えつつ、解釈性も高めたい場合。特に、多数の特徴量があり、それらの中に重要でないものが混在している場合に有効
有効な場面(決定木回帰モデル編)
決定木回帰モデルは、データの複雑な構造を捉える能力に加え、欠損値が意味を持つ場合の分析にも優れています。 一般的に、欠損値はデータの収集工程や測定の限界、工場の異常停止など様々な理由で発生しますが、時にはそれ自体が重要な情報を伝えることがあります。
たとえば、ある調査項目に対する回答が欠損している場合、その欠損自体が特定の行動傾向や属性を示唆する可能性があります。
決定木モデルは、このような欠損値を意味のある情報として取り扱うことができます。決定木は欠損値をそのまま分岐の判断材料として使用でき、欠損を特定のパターンとしてモデル内で表現することが可能です。 データの欠損がランダムでない場合にも、その背景にある潜在的な情報を捉えることができます。
- 例えば
- データに急激な変動や非線形なパターンが含まれている場合
- カテゴリ変数が多く含まれるデータセット
- 欠損値が意味を持つ可能性があるデータセット
- 注意点
- 欠損値を有意な情報として扱う場合、その欠損がランダムでないことを確認し、その背景を理解する必要がある
- 決定木は学習データに対して過剰適合しやすいため、モデルの複雑さと解釈可能性のバランスを考慮することが重要
※カテゴリ変数とは、一定の区分に基づいて分類されるデータのことを指します。 これらの変数は通常、文字列や記号で表され、その数値的な大小や差には直接的な意味がありません。 カテゴリ変数は質的データとも呼ばれ、データの属性や種類を表すのに適しています。
例えば、アンケートでの評価「良い」「普通」「悪い」はカテゴリ変数です。 これらの評価は「1」「2」「3」という数値に変換されることがありますが、これらの数値は単に異なる評価を区別するためのものであり、数値間の差が特定の量的意味を持つわけではありません。
有効な場面(MLP 編)
MLP は、データ内に非線形かつ複雑な関係が多く含まれている場合に有効なモデルです。例えば、株価の終値予測などは、経済の状況といった様々な要因によって変動するものなので MLP が有効になる場合があります。
- 例えば
- データが大量にある場合
- データが非線形の関係にある場合(※1)
- 予測精度を重視する場合
- 注意点
- データが少量の場合、望む精度が得られない場合がある
- 他のモデルと比較するとモデルの解釈性が低い(※2)
※1 線形/非線形とは:線形とは、幾何学的には「まっすぐ」なことを指します。例えば、直線や平面は線形に該当しますが、曲線や曲面などは線形とは呼ばず、非線形な対象となります。
具体的には、以下の図のようなデータです。ただし、現実には完全な直線になるデータは少なく、一定の上昇/下降傾向があるようなデータが線形なデータに当てはまる場合があります。

※2 ただし、一般的には解釈性が低いとされる MLP においても 「どの入力が、どのようにして」出力に影響を与えているのか、要因を分析することで解釈性を高めることも可能です。
まとめ
本記事では、時系列分析で用いられる数理モデルの概要を紹介しました。 時系列分析においては、データの特徴を理解し、分析対象のデータに合っているか判断することが重要です。 また、AI モデルを現場に導入する際には、AI モデルの解釈性も重要となりますので、要件に合わせて適切なモデルを選択することが必要です。
最後にここでは触れていませんが、発展的な内容として 2017 年度に発表された Transformer など、他分野の技術が時系列分析にも応用されることがあります。 詳細はごちきか:Informer (AAAI2021 Best Paper)をご覧ください。