
編集日
2024年6月
カテゴリ
分析設計/データ理解
目次
はじめに
本記事では、具体例として電力需要の予測問題を取り上げ、問題設定から、モデル評価までの事例を紹介します。この事例を理解し真似ることで、自身のデータに対する問題設定の仕方とその解決方法を見つけ出し、自らの手で需要予測を行う手順をイメージできるようになります。
事例紹介
事例
本記事では、「オーストラリアの電力需要量」を予測します。
問題設定
問題設定とは、データを使って明らかにしたいことを定義することになります。
定義のためには、分析の目的を明らかにするだけでなく、分析アプローチや評価指標の選定含めた分析デザインを行う必要があります。
以下は、問題設定のための手続きの一例となります。
課題定義と分析仮説:
予測の目的を具体的に定義します。今回は具体的に、特定の日時で予測したい需要量(例: 30 日後の日別電力需要量)に焦点を当てます。 予測結果がどのようにビジネス目標に貢献するか分析による仮説を考えます。例えば、需要予測に基づいた適切なリソース配分や販売戦略の最適化を目指します。データの準備:
使用するデータセットの特性を把握し、データの前処理を行います。この段階で行う作業は多岐にわたります。
たとえば、データセットには予測に不適切な要素(欠損値、外れ値、文字列など)が含まれている場合、これらを適切な値に変換する必要があります。
また、異なる尺度や範囲を持つ複数の特徴量を持つ場合は、外れ値の影響軽減のために、正規化を行います。
他にも、データに周期性がある場合は、予測に用いるデータの長さを周期性に合わせて調整します。さらに、予測精度向上に寄与しない不要なデータを明らかにして削除したり、予測精度向上に寄与する可能性のある新しいデータ(例: 休日情報)を見つけて追加することがあります。
モデル作成後も、予測精度を向上させるために、適宜データの特性を再評価し、適切な前処理を試行することが重要です。これにより、より正確な需要予測が実現します。
※ 細かな前処理の説明は まずは、前処理を考えよう を参照ください。モデリング・評価:
予測に使用するアルゴリズムを選定し、モデルの構築と評価を行います。アルゴリズムとそのパラメータによって予測精度は異なるため、精度向上のためにはモデル構築と評価の試行錯誤が必要です。 また、成果を評価するための指標を選定します。Node-AI では、平均絶対誤差(MAE)や平方根平均二乗誤差(RMSE)などを選択できるので、要件に合わせて評価指標を参照してください。
以上のステップを通じて、効果的な電力需要予測の実現を目指します。
分析の戦略を立てる
今回のケーススタディの場合、 5 年分の過去データを使って、「30 日後」の「オーストラリアの日別総電力需要量」を予測する、と定義します。
また、電力需要予測は、電力業界における効率的な運営と資源管理に欠かせない要素です。正確な需要予測により、発電計画の最適化が可能となり、過剰な発電や電力不足を防ぐことができます。これにより、コスト削減による事業の安定化と、安定供給による消費者からの信頼向上が実現します。
つまり、正確な需要予測により、事業への貢献と利用者への提供価値を高めることを目指します。
データの準備
データセットの紹介
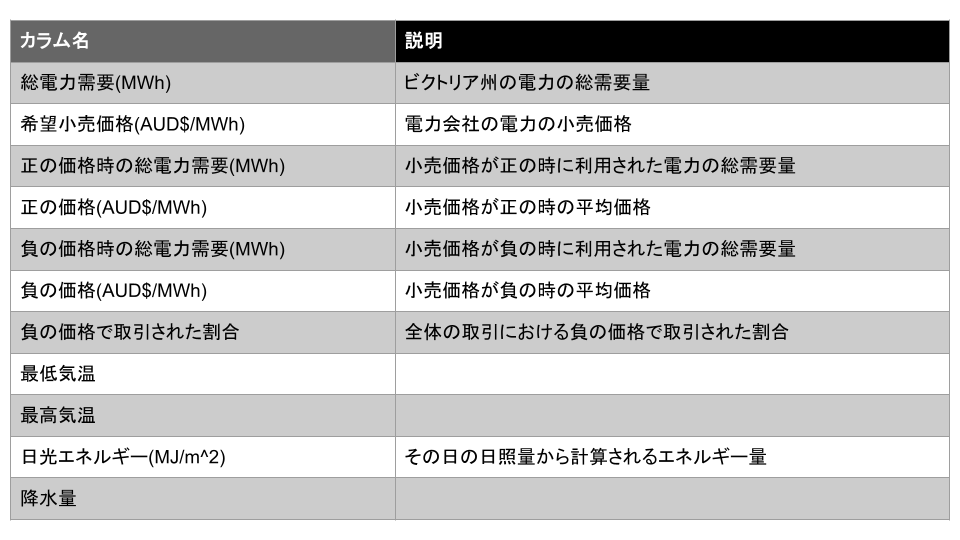
今回は、オーストラリアの電力需要予測データセットを用います。本データセットは、1 日ごとの電力需要量、電力価格、最低気温、最高気温、日光エネルギー、降水量などが含まれており、過去 5 年間にわたる詳細な情報が揃っています。
気象条件や価格変動が電力需要に与える影響を分析し、精度の高い需要予測モデルが構築できないか考えます。
また、本データは Node-AI の「公開データ」よりいつでも利用できるので、本記事と併せてお試しください。
データの性質
欠損値の確認
欠損値は、データの中で欠落している値のことを指します。これは、データ収集の過程でのエラー、測定の不正確さ、または単に情報が得られなかった場合などに起こります。今回は、機器のエラーに依るものと判断し、欠損値の補完をします。
Node-AI では、カードを開くと、プロパティ欄にて「欠損値」が存在することがわかります。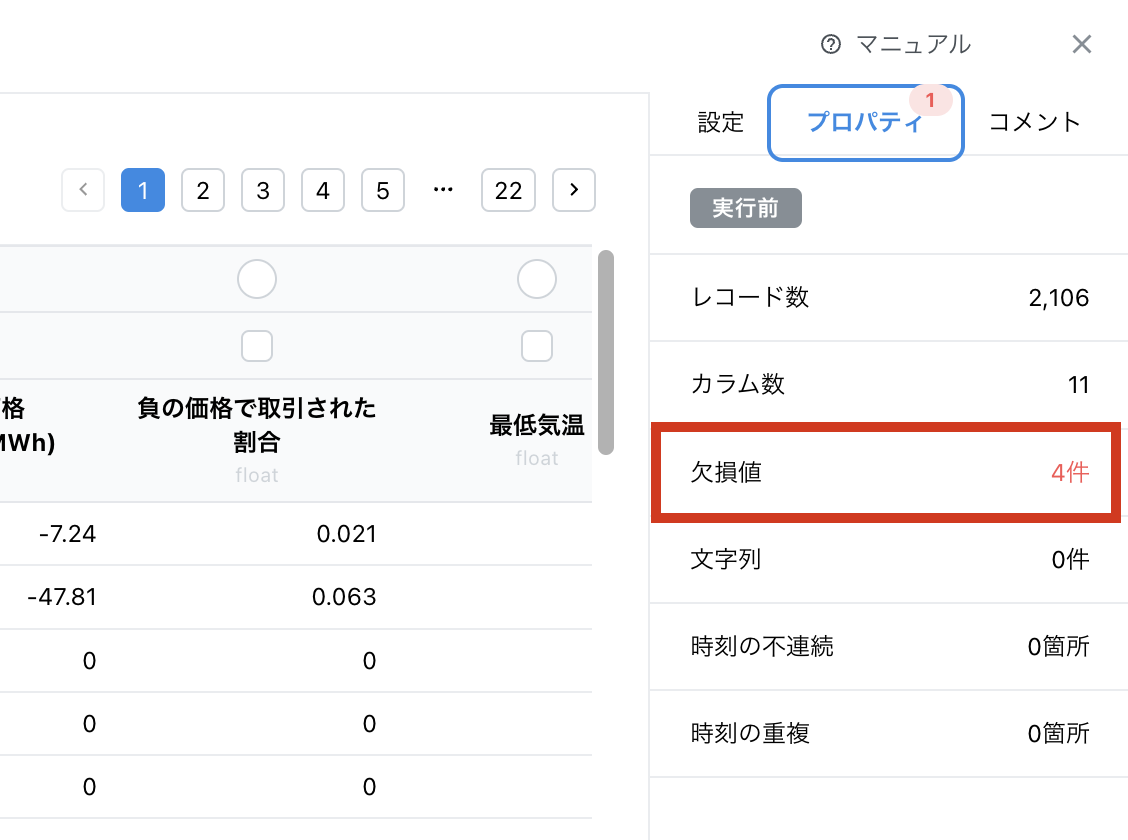
また、統計タブを確認することで、データセットの中の「欠損値」「外れ値」を確認することもできます。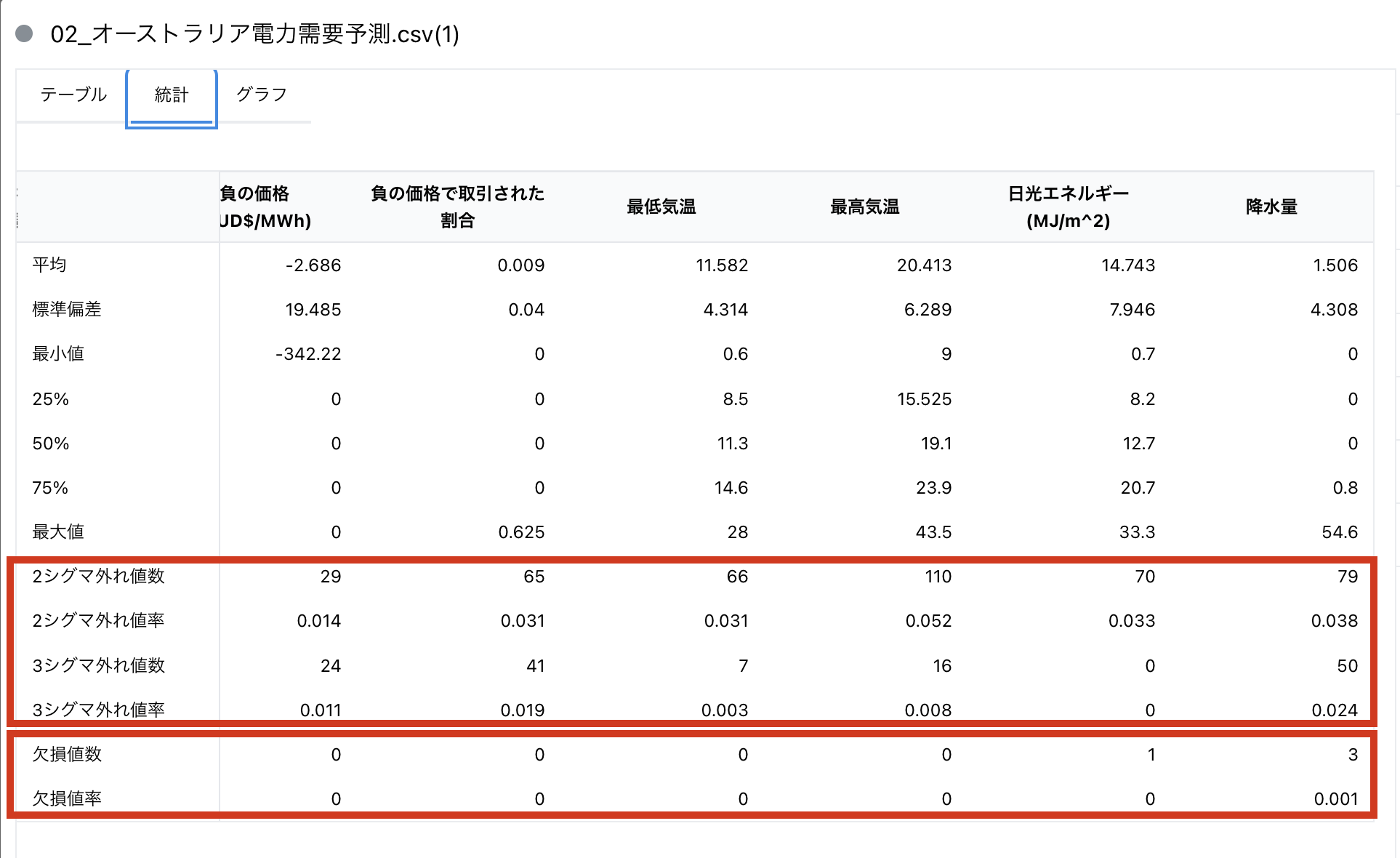
上記欠損値を埋めるためには、 欠損値補間カード を利用してください。
周期性の確認
周期性の確認のために、自己相関を見てみます。自己相関とは、時系列データの異なる時点間での相関関係を指します。
つまり、自己相関が高いとは、データの過去の値が未来の値に影響を与える可能性が高く、自己相関が低い場合はデータがランダムであり、未来の値は過去の値からは予測しづらいことを示します。
Node-AI では、自己相関分析 カードを用いることで確認できます。
結果を確認すると、7(日)の位置で相関が高く出ています。つまり、総電力需要の値は 7 日(=1 週間)前の値から予測しやすいことがわかります。つまり、学習に用いるデータは 7 日以上の長さのデータであるべきだとわかります。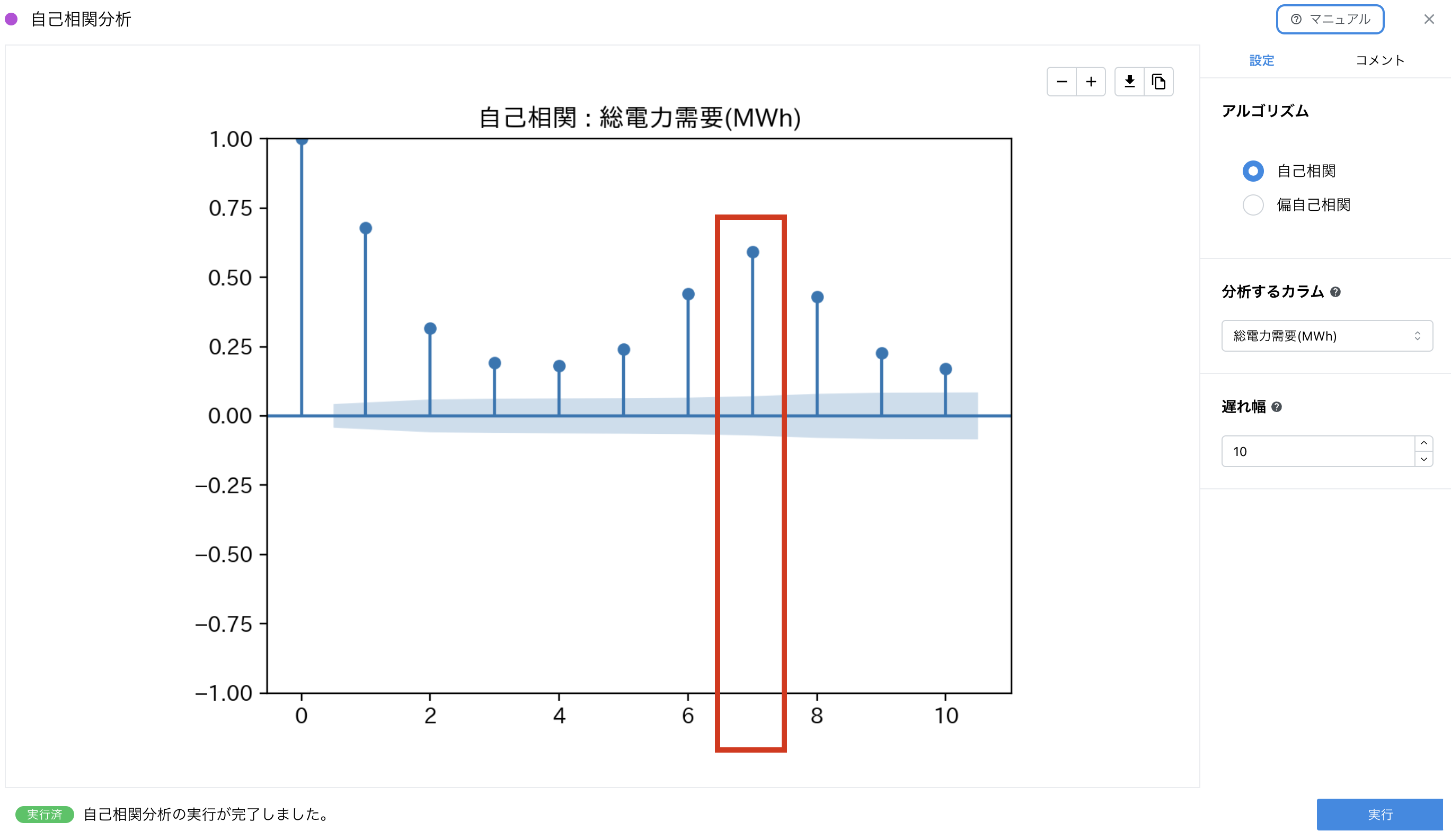
正規化の実施
AI モデルの学習では多くの場合で値(絶対値)の大きい列の影響が大きくなります。(例外もあります。) そのため、単なる値の大きさから発生する影響の差を無くすために正規化と呼ばれる処理を行います。 カードのグラフタブを見ると、スケールが違うことが明かであることがわかります。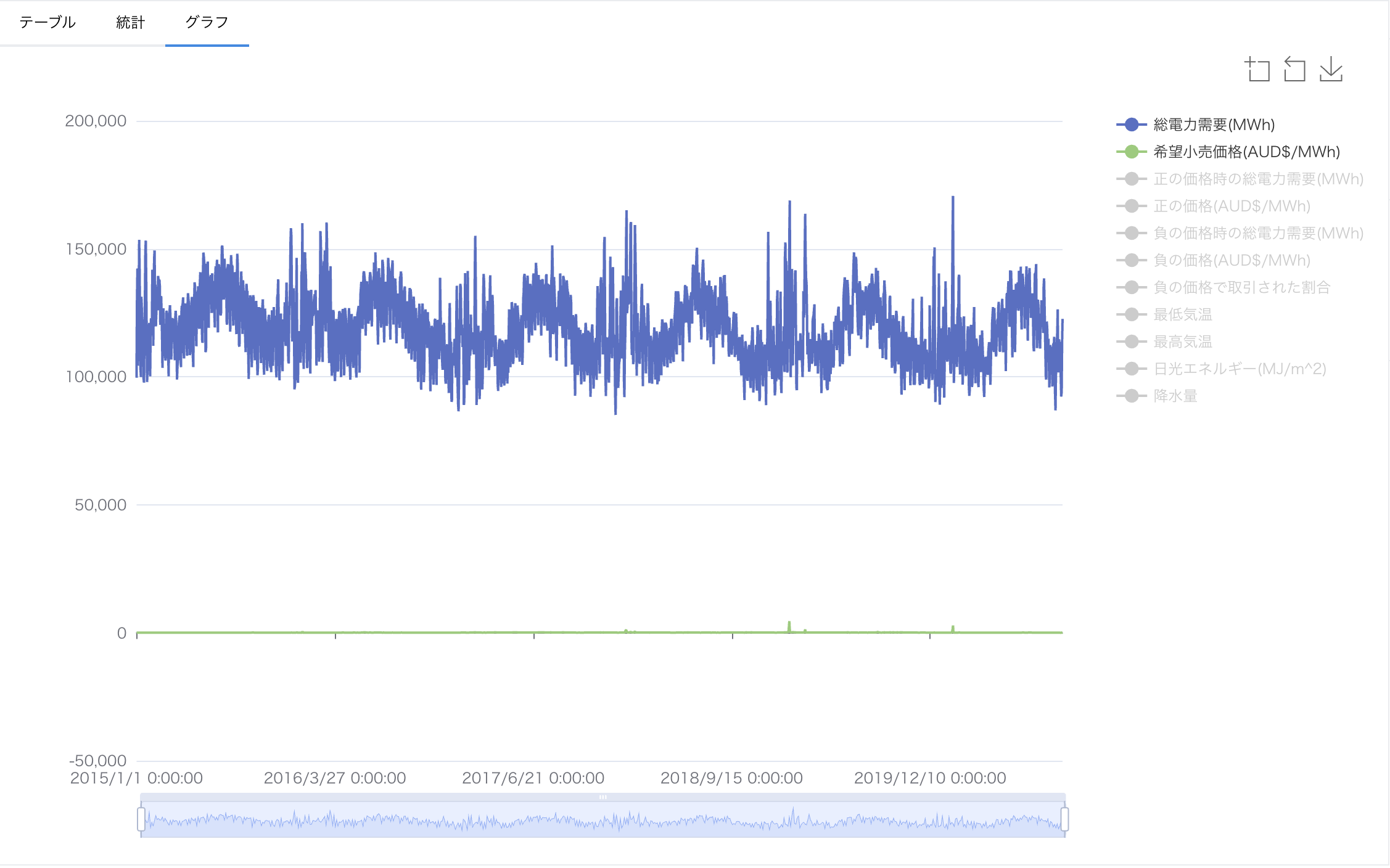
値を特定の数値の範囲内にスケールさせるために、Node-AI では、正規化カード を利用してください。
時間窓の設定
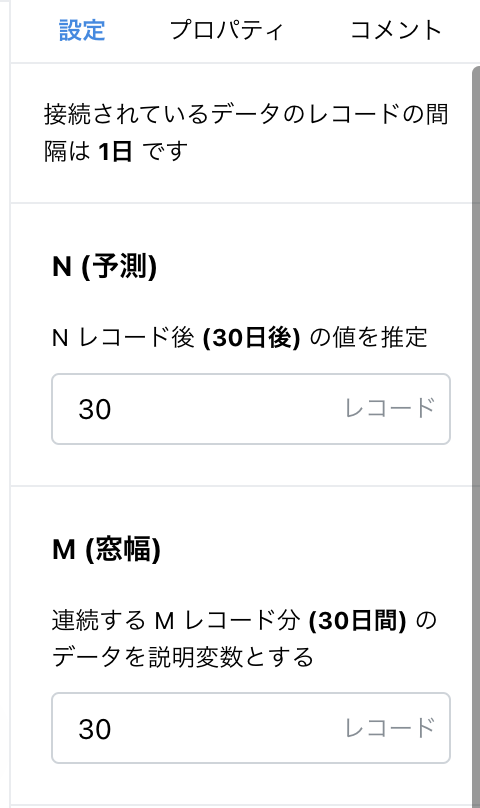
目的設定(=30 日後の総電力需要量予測を行いたい)と、データの特徴から予測に用いる設定を行います。Node-AI では、時間窓切り出しカード を利用します。
モデリング・評価
モデルの選定
データ分析において、適切な分析モデルの選定は重要です。主な分析モデルの特性と選定のポイントについては時系列分析で用いる数理モデル に関する記事を参照ください。
Node-AI では、MLPカード, 線形モデルカード, 決定木回帰モデルカードを利用できます。
以下は、線形モデルを用いた例となります。

上記を踏まえ、学習までを以下の構成で実行します。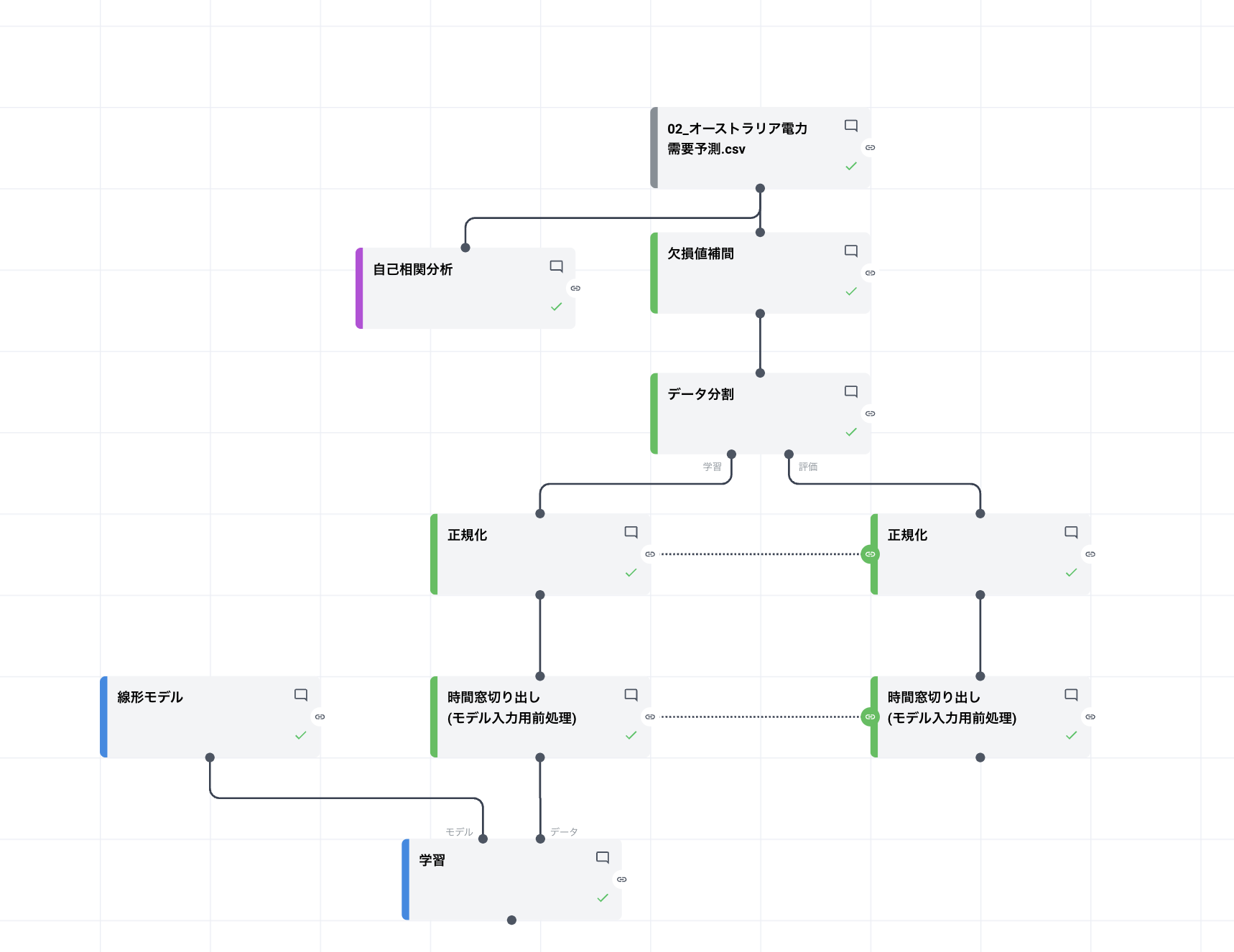
評価 学習まで完了したら、モデル評価(相関係数/決定係数) および モデル評価(MAE/RMSE) を参考に評価指標を確認します。
Node-AI において、評価カード を実行し、精度を確認します。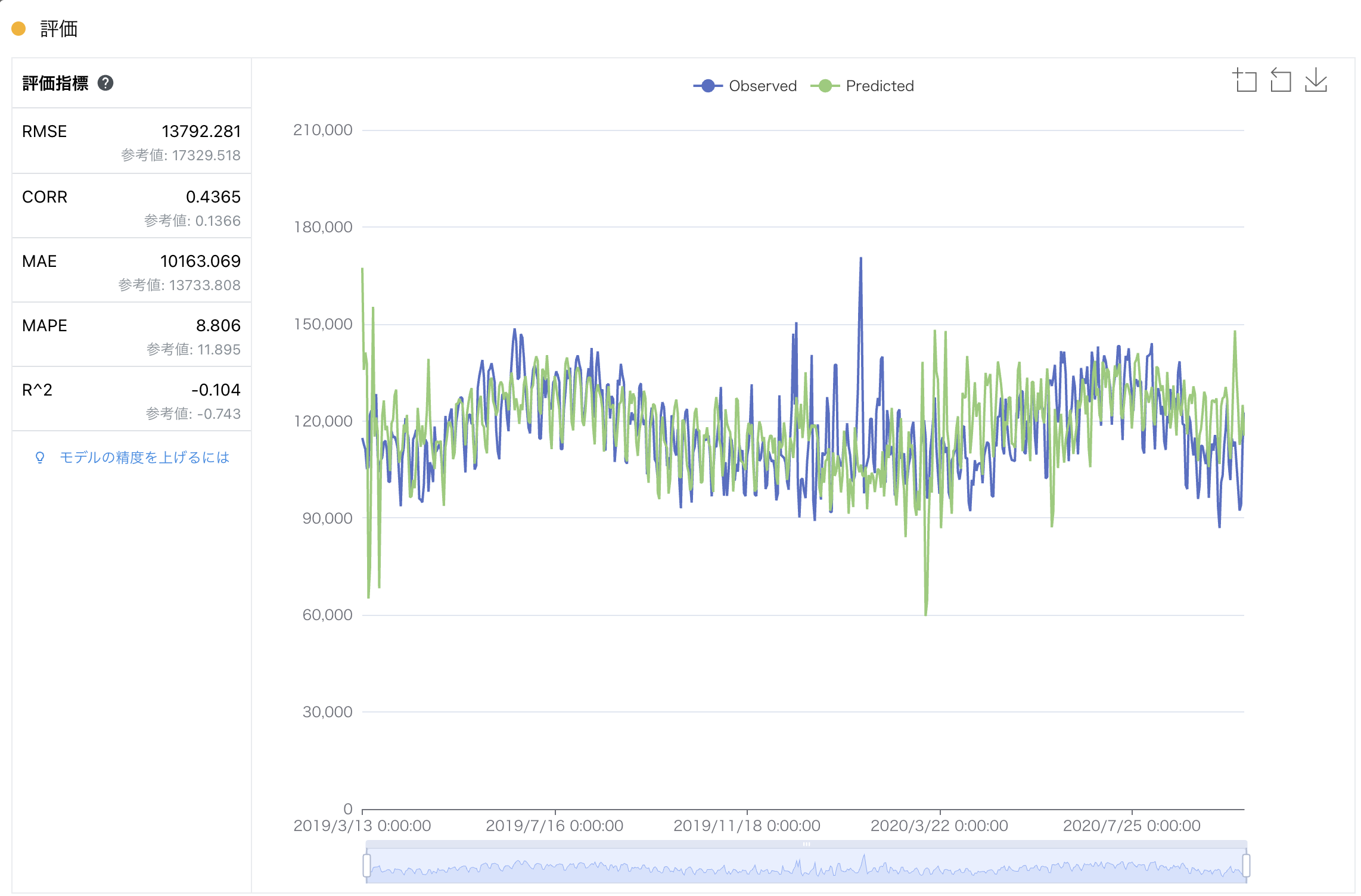
おわりに
データ分析において、問題設定はプロジェクトの成否を左右する重要なステップです。問題設定が不適切であれば、どんなに優れた分析手法やモデルを使っても、有用な結果を得ることは難しいでしょう。
問題設定では、特に、ビジネス目標に直結した分析目標を明確にすることと、データの特性が分析目標に適しているかを慎重に検討する必要があります。
この作業はデータの性質や業界の特性、顧客のニーズなどを深く理解することが求められ、複雑なビジネス環境では多面的な視点が必要です。また、データの収集段階で問題が発生することも多く、現実のデータは欠損値や外れ値などを含むことが一般的です。これらの課題をクリアするためには、ドメイン知識を熟知した上で、適した分析手法を試していく必要があります。
最終的に、適切な問題設定は効果的なデータ分析と意思決定を可能にし、ビジネス価値を最大化するための鍵となります。