
編集日
2024年6月
カテゴリ
分析設計/データ理解
はじめに
「データ分析ってなんか難しそう…」「興味はあるけど、何から始めたらいいか分からない…」そう感じているあなた、ひとりではありません! 多くの分析初心者が同じ悩みを抱えています。そういったみなさんに向けて、本記事でベースラインという考え方を知ってもらいデータ分析の第一歩を踏み出していただる手助けになれば嬉しいです。
目次
ベースラインとは
データ分析の全体像:CRISP-DM モデル
Node-AI で実践
ベースライン作成後
1. ベースラインとは
「ベースライン」とは、データ分析の骨組みとなる、最小限の分析フローのことです。 まずはこのベースラインを作成することで、データ分析の全体像を把握し、後々の分析をスムーズに進めることができます。
例えば、家を建てる時を想像してみてください。いきなり壁や屋根を作らずに、まずは家の骨組みを作りますよね? データ分析も同じです。詳細な分析を行う前に、まずはベースラインという骨組みを構築することが重要です。そして、この次のステップとして骨組みへの肉付けを行っていく「特徴量エンジニアリング」や「パラメータチューニング」といった詳細な分析フローが存在します。
本記事ではこの「骨組み」を作る部分にフォーカスしています。 具体的には、以下のステップを順番に実行することを指します。
分析の戦略を立てる:どんなデータをどのように分析したいかの方針を立てる
データの準備:分析を行いたいデータに必要な加工をして整える
モデリング・評価:準備したデータでモデルを構築してどの程度の精度なのか評価する
このベースラインは、あくまで「骨組み」なので、最初は粗くても問題ありません。重要なのは、データ分析の一連の流れを作り上げることです。
ベースラインを作成することで、以下のメリットがあります。
データの特性や課題の早期発見
ベースラインを通して、データの全体像を把握し、データの品質や潜在的な問題点を早期に発見できます分析の方向性の明確化
ベースラインの結果を踏まえて、どのような分析手法を採用すべきか、どのような特徴量を検討すべきかなど、分析の方向性を明確化できますモデルの良し悪しを判断する基準
ベースラインのモデルの性能を基準とすることで、後々に作成する高度なモデルの性能を適切に評価できます
ベースラインは、データ分析のスタート地点です。
まずはベースラインを作成し、データ分析の全体像を把握することから始めましょう。
2. データ分析の全体像:CRISP-DM モデル
このベースラインの考え方で非常に参考になるのが CRISP-DM モデルというものです。CRISP-DM は CRoss-Industry Standard Process for Data Mining の略称でありデータ分析プロセスのモデルとなっています。このモデルに沿って取り組むことでデータ分析を効率よく行うことができます。
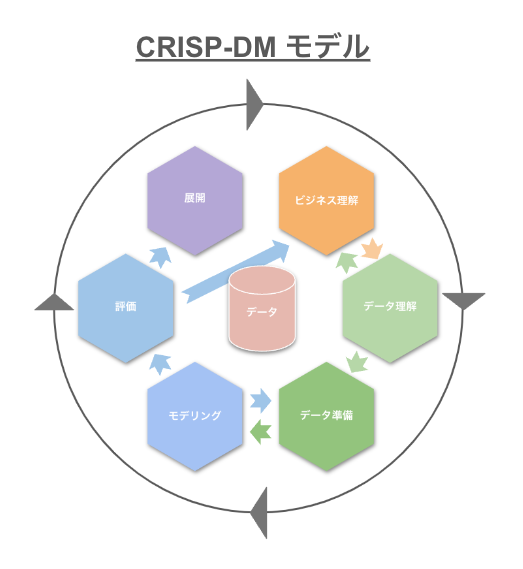
CRISP-DM モデルでは、分析プロセスを以下の 6 つの段階に分けます。
ビジネス理解: 分析の目的や目標を明確にする
データ理解: どんなデータがあり、どんな特徴を持っているかを理解する
データ準備: 分析に適した形にデータを加工する
モデリング: データに基づいて予測や分類を行うためのモデルを構築する
評価: モデルの性能を評価する
展開: 構築したモデルを実用化する
これらのステップは、必ずしも順番通りに進める必要はなく、行ったり来たりしながら進めていくこともあります。よく見ると上述した「骨組み」のためのフローをより具体化したものになっていることがわかります。
ただ、少し煩雑に見えるところもあるので分析プロセスを Node-AI で実践するならどうなるのか? という観点で以下の 4 つの段階に分けて考えてみたいと思います。次章で各段階の特徴とベースラインを作るという観点でのポイントを解説します。

3. Node-AI で実践
Node-AI で上記フローを実践することでより具体的な分析の第一歩を踏み出せるようにしていきましょう!
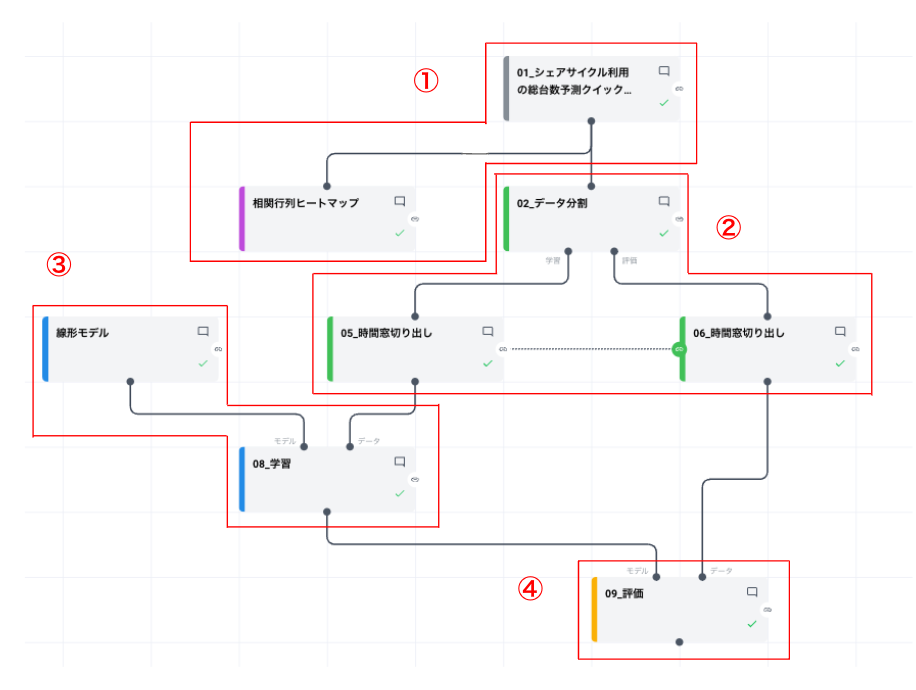
3.1. 分析設計
最初に分析の方針を立てます。ここでは例として、上図のシェアサイクルデータ(詳細はこちら)に対して「貸し出し台数を最適化する」という目的のもと「将来の需要量を予測する回帰問題として課題を設定する」という分析方針を立てます。
次に分析する上で重要なデータ把握にもフォーカスします。まずは、データのアップロードについてです。アップロードしているデータがなければ下図の中央から「ローカルファイル」もしくは「公開データ」をクリックしてアップロードできます。既にデータがアップロードされている場合には右上の「データの追加」をクリックしてアップロードできます。
※ データのアップロードに関するマニュアルはこちらです。
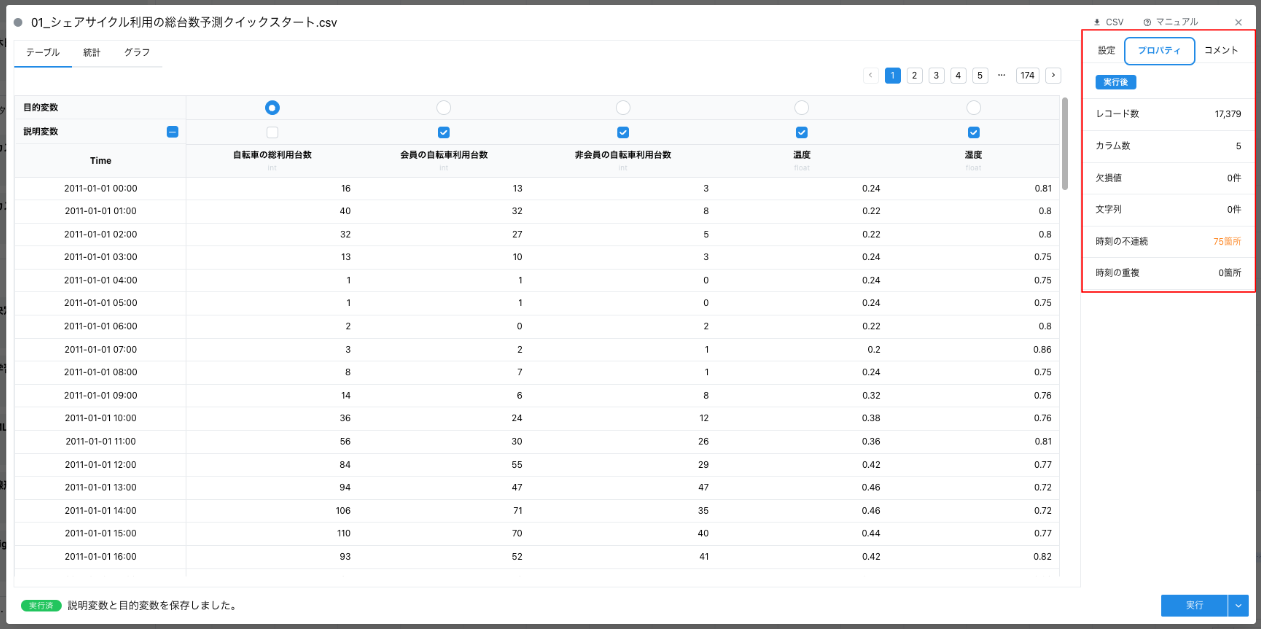
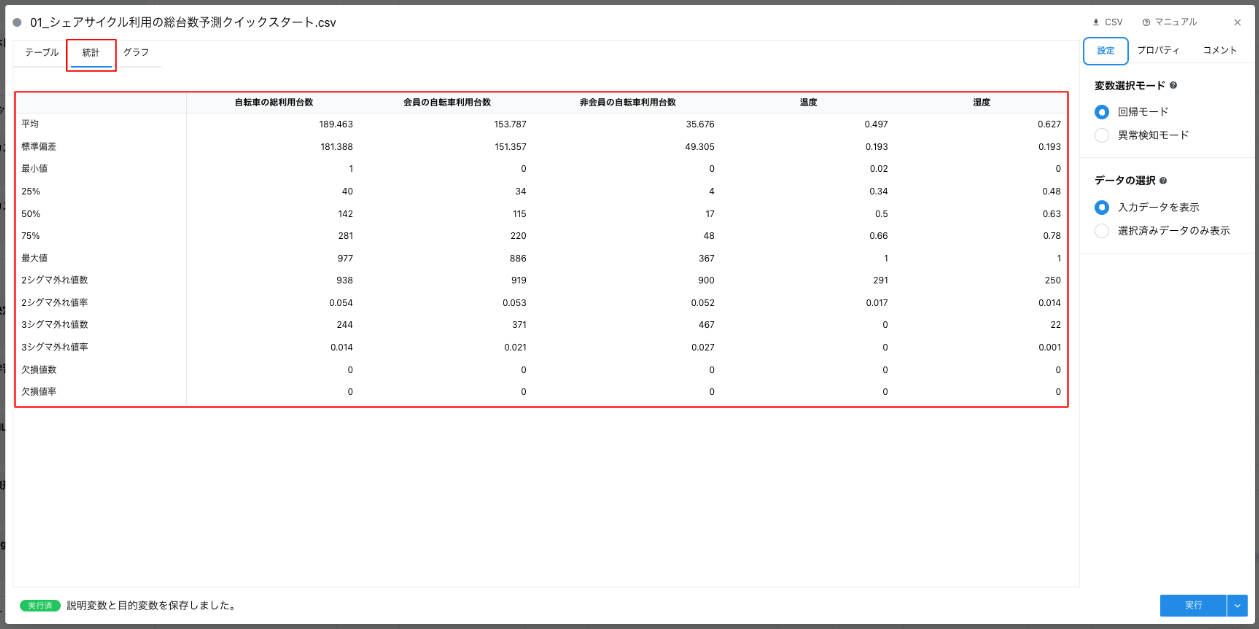
データの全体像の理解も重要です。方法は 2 通りあります。1 つは、データリソースカードの「プロパティタブ」と「統計タブ」です。これらのタブは一部を除くカードに共通しており、「プロパティタブ」では多くの場合で前処理を適用する必要がある欠損値や文字列について確認できます。「統計タブ」ではそれらを含む指標も確認できデータの全体像の把握に役立ちます。
- プロパティタブ
- 統計タブ
もう 1 つは、可視化カードの利用です。例えば、「相関行列ヒートマップ」で相関のありそうな特徴量を行列で見ることができます。
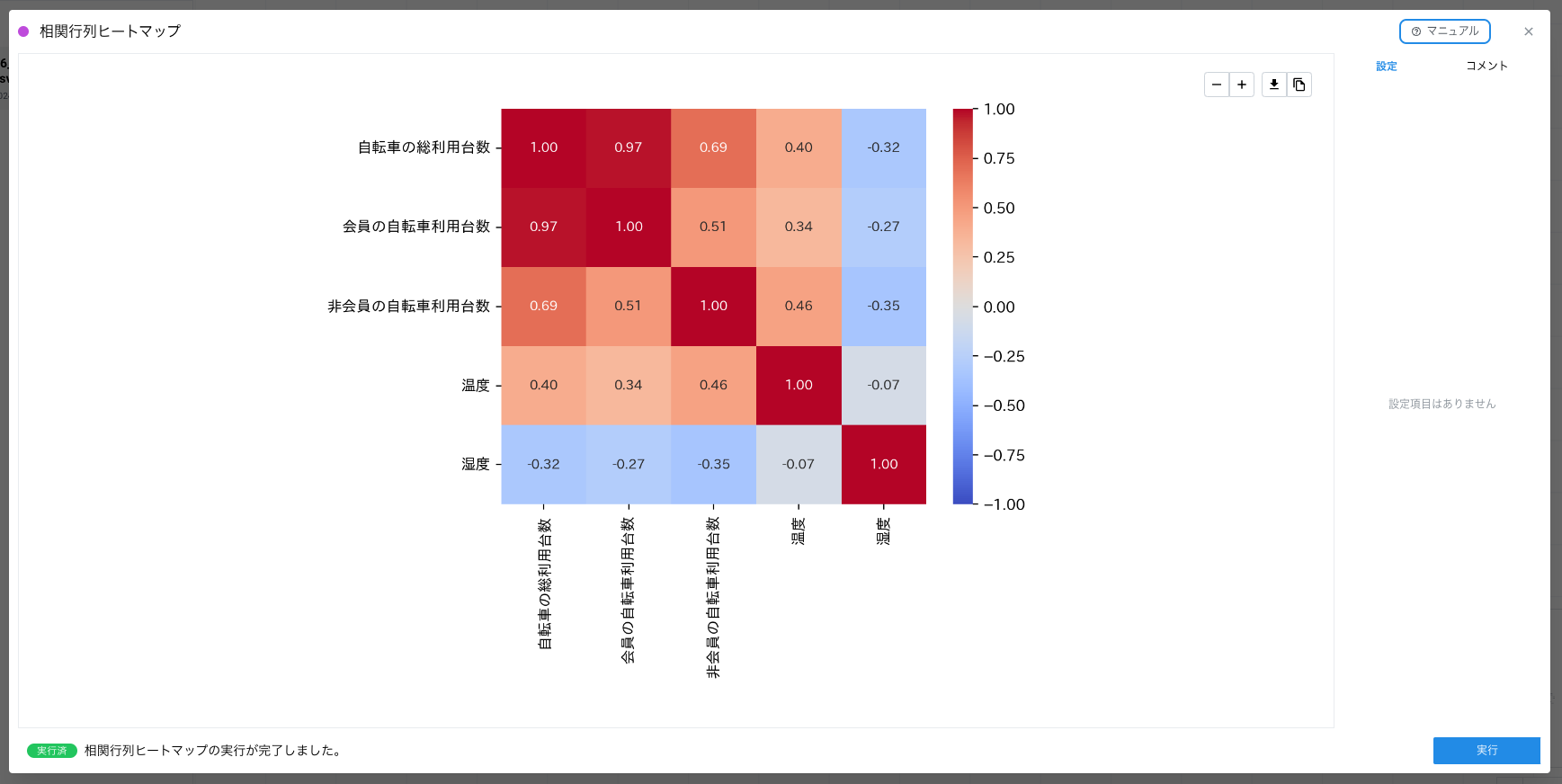
このようにデータリソースカードや可視化カードによって、分析を設計する上で重要なデータの全体像の理解を行えます。
※ データの可視化に関するマニュアルはこちら。
3.2. データ準備
モデルを構築する上で適切な形に整える前処理の行程です。 欠損値を補うための「欠損値補間」や学習カード・評価カードに繋げるために必要な「時間窓切り出し」などの多くの前処理カードがあります。
例えば、「データ分割」の前処理カードを利用するとデータを任意の学習データ期間と評価データ期間に分割できます。
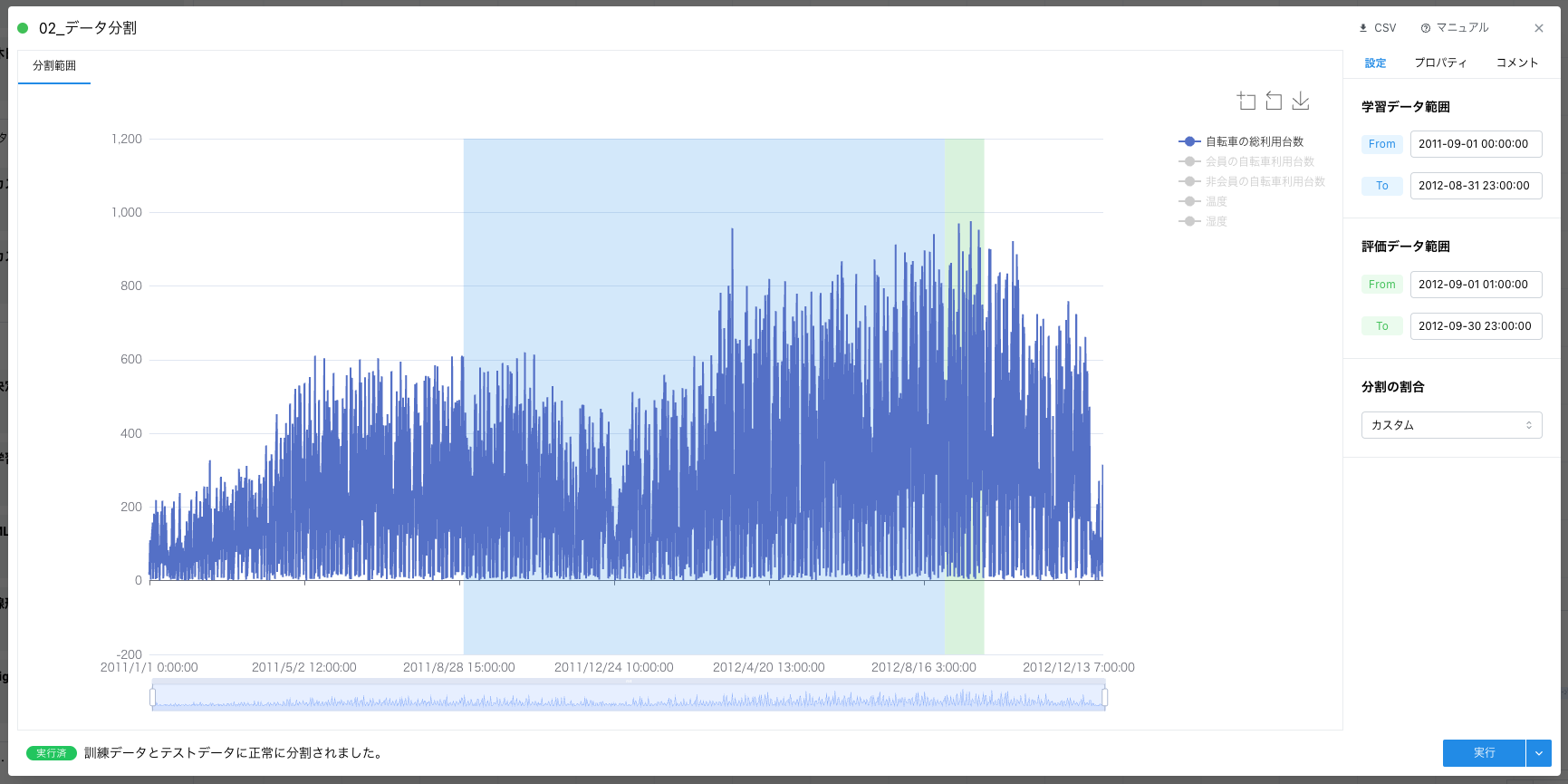
このような前処理カードを複数組み合わせることでモデル構築に適した形にデータを整えていきます。実際のキャンバス画面では前処理カードが多く何をしたら良いか迷ってしまうかもしれませんが、ベースラインを作るという意味では多くのカードは必要とせず後述する「学習」カードが実行できる程度の前処理があれば十分です。
分析対象のデータを任意の割合で分割するための「データ分割」(参考記事はこちら)
機械学習モデルがデータを学習可能にするための「時間窓切り出し」
※ データの前処理に関するマニュアルはこちら。
3.3. モデリング・学習
実際にモデルを構築する行程です。 シンプルなモデルである「線形モデル」や深層学習モデルである「MLP」を含む複数のモデルカードがあります。

構築するモデルが決められたら学習カードによってモデルを構築します。
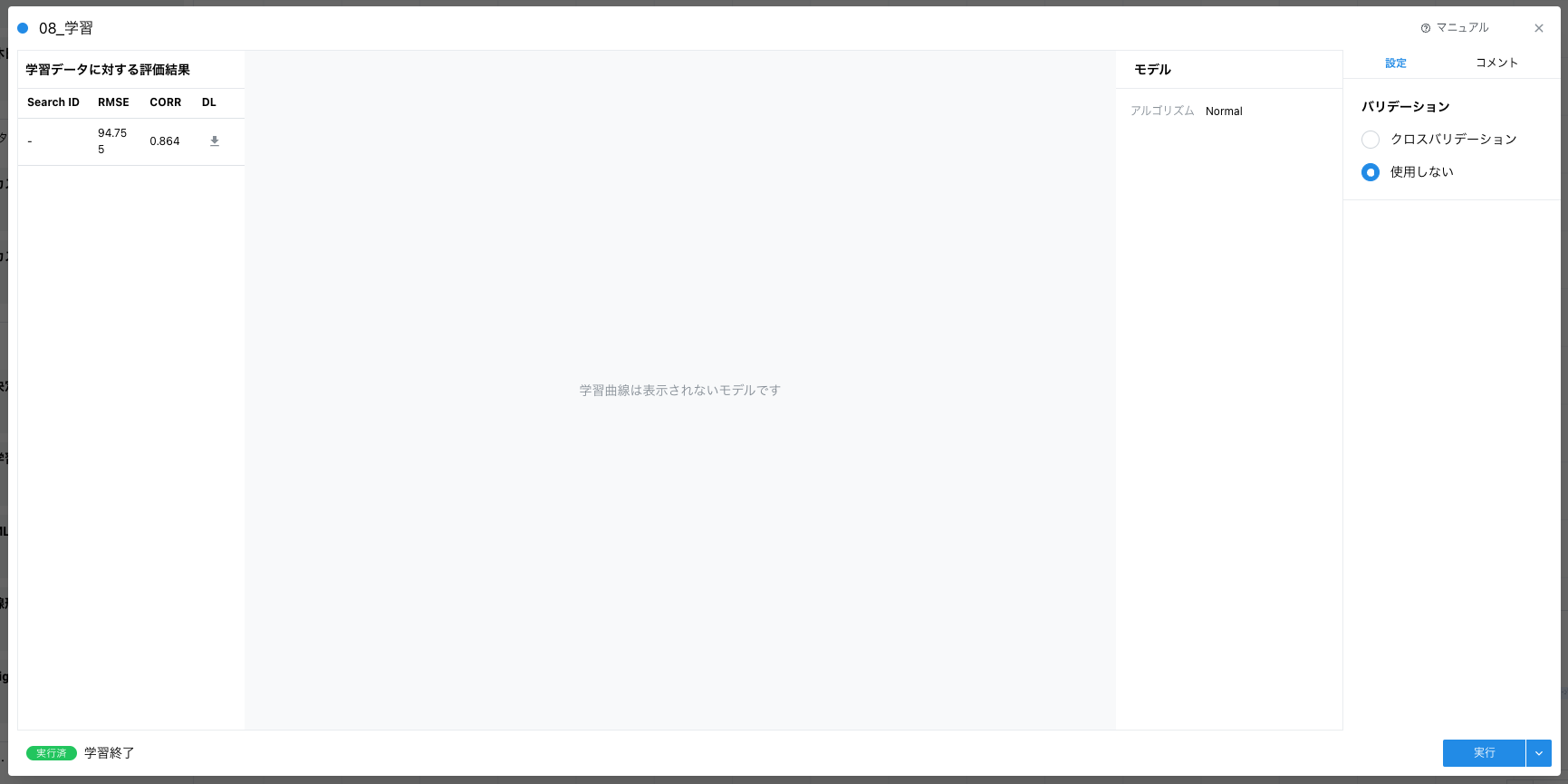
モデルカードはまだまだ少ないですが、今後追加して分析の幅を広げられるようにする予定です。ベースラインを作るという意味では、悩むポイントが少ない下記のモデルカードを利用するのがおすすめです。
- 設定値が少ない「線形モデル」
※ モデルに関するマニュアルはこちら。
※ 学習に関するマニュアルはこちら。
3.4. 評価
最後に構築したモデルを評価するために学習カードと分割したもう一方のデータを評価カードにつないで実行します。
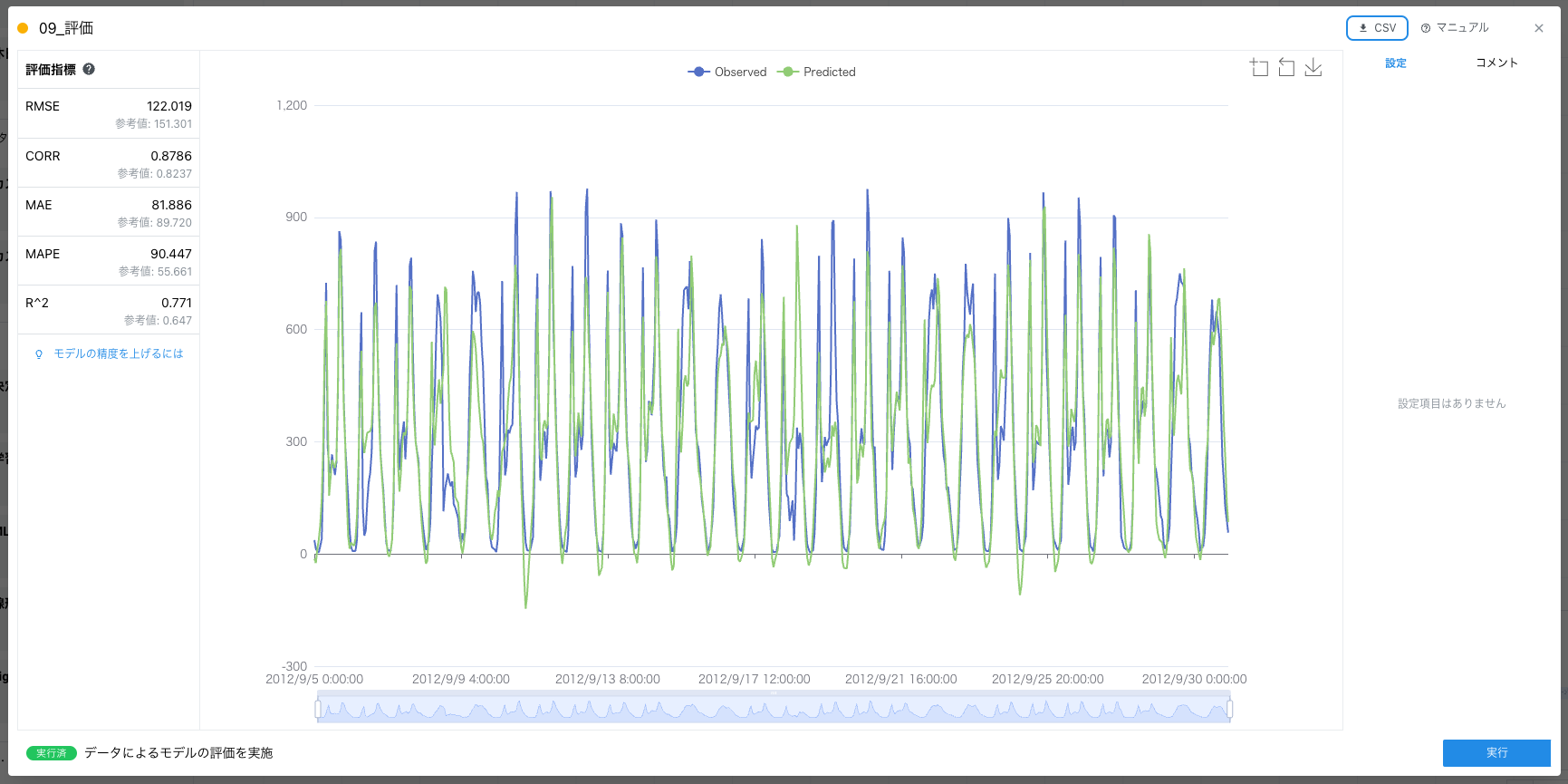
実行後に左パネルに評価指標が表示されます。ここに表示された値は今後精度向上させる上での基準になります。ということで、ベースラインを作るという意味では、ここまで到達したことで目的を達成できたことになります!
このように Node-AI でベースラインを考えを実践するにはモジュールパネルにあるカード群を必要最低限の構成でツリーを構築することで実現できます。難しそうに見えた方は、トレーニングチームにあるチュートリアルに取り組むことをおすすめします。実際に手を動かすことで、こちらに書いてある内容を実感できるかと思います。
※ 評価に関するマニュアルはこちら。
4. ベースライン作成後
ベースラインを作成した後は、ビジネス課題に対する目標達成度を確認します。 これは、作成したモデルの精度が目標値を満たしているかどうか検証することを意味します。
ベースラインモデルが目標値を達成している場合、その時点で本番運用に移行できます。一方、目標値を満たしていない場合はさらなる精度向上が必要です。 モデルの精度向上にはさまざまなテクニックやアプローチがありますが、これについてはモデルの精度を上げるにはをご参照ください。
ここまででデータ分析のプロセスが 1 周しました。 ベースラインを作成することで、その後の精度向上に集中できます。
どのプロジェクトにおいても、まずはこの全体プロセスを最初に構築するようにしてください!