
編集日
2024年6月
カテゴリ
前処理/可視化
はじめに
データ分析を始めようと思い立った時に、一番最初にやるべきことは分析対象のデータの全体像を把握し、利用したいモデルや分析手法に合わせる形でデータを整形することです。
多くの場合、データに対して前処理は必要不可欠になります。そのため、この記事では、利用したいモデルや分析手法を実行するために必要となる前処理を考えるために、データに対して簡易的に確認すべき項目を 3 つご紹介します。
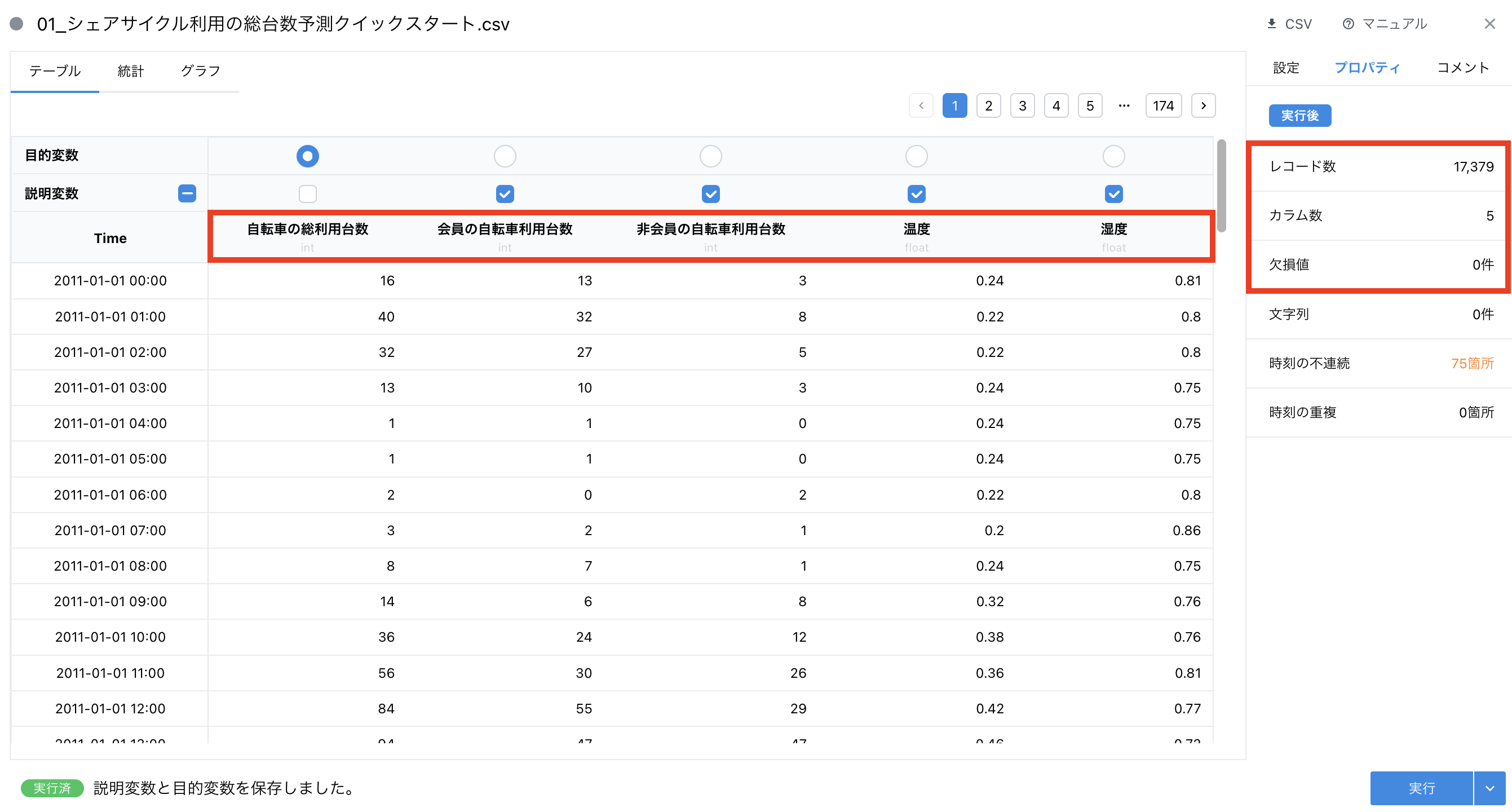
Node-AI のデータカードでも、今回紹介した項目を簡単に確認できるので、Node-AI の画面と照らし合わせながら確認していくことをオススメします。
データの大きさを把握しよう
まず、データのレコード数とカラム数を確認しましょう。レコード数とカラム数が大きい場合、目的とする分析精度を達成する上で必要のないレコードやカラムを削除するなどの前処理が必要になります。 一方で、レコード数とカラム数が少ない場合は、以下のようなリスクが考えられます。
- データが極端に不足しており、精度目標を達成できない。
このリスクに対する具体的な前処理としては、既存のデータに対して、外側からデータを付け加えるなどの方法があります。
変数の意味を確認しよう
データの大きさを把握するのと一緒に、変数の意味を確認しましょう。
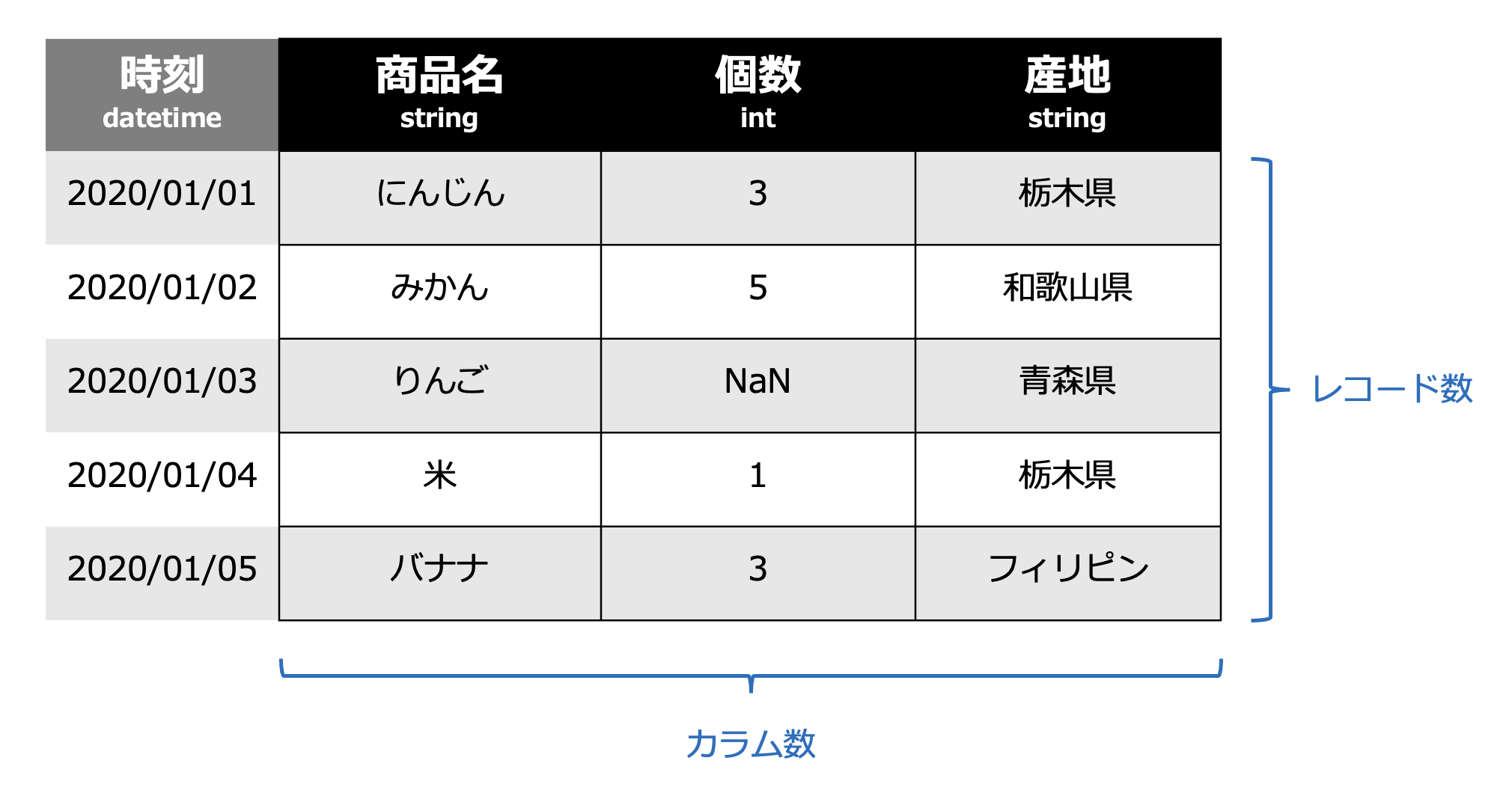
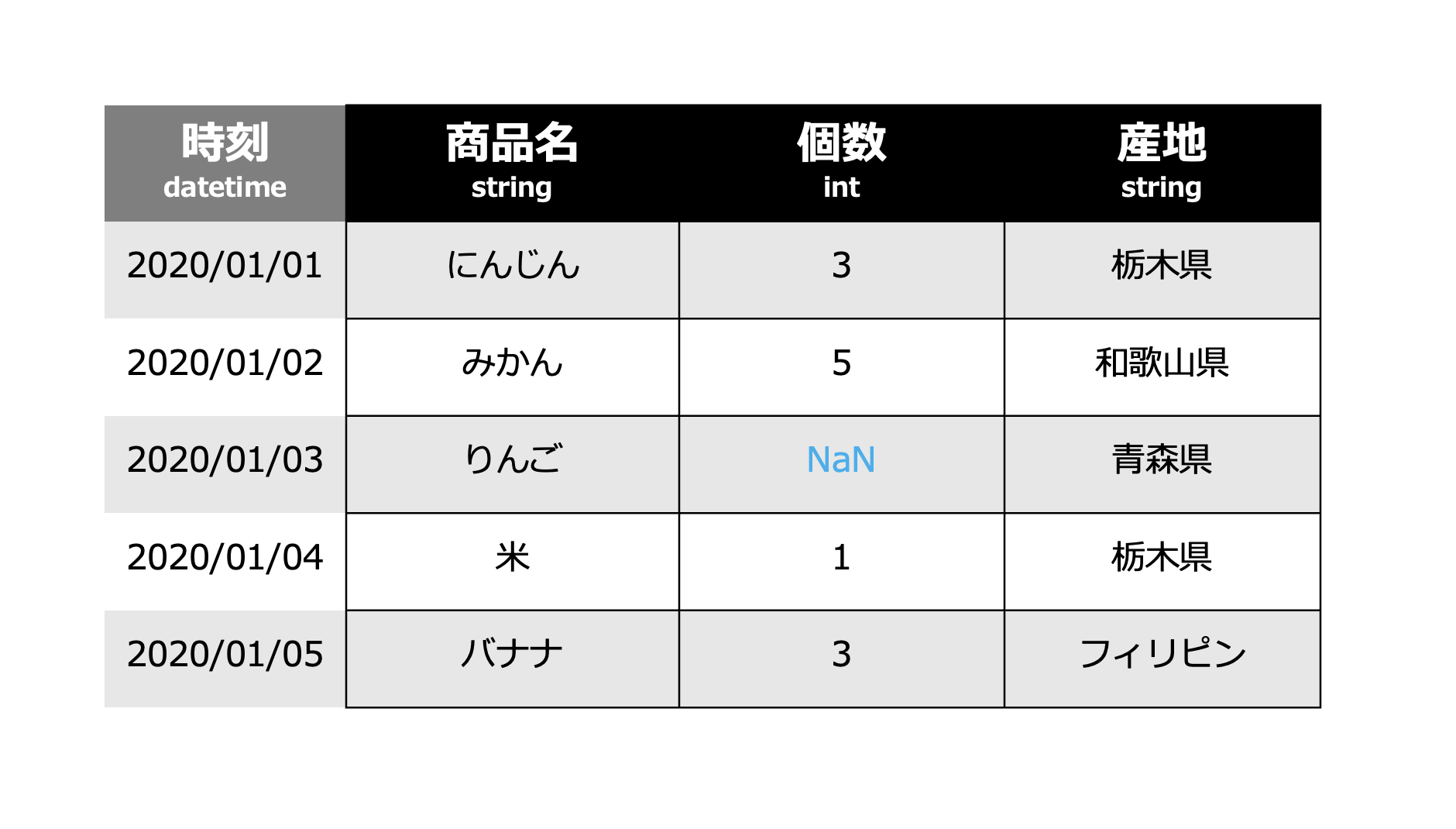
具体的に考えてみましょう。上記のデータは、どのようなデータでしょうか?
商品名、個数、産地のカラムがあり、商品名にはにんじん、みかん、りんご、米、バナナが含まれてます。個数は、各商品に対する個数を表しており、産地は各商品がどこで収穫されたのかを表しており、日本国内であれば都道府県単位、海外であれば国単位になっていることがわかります。時刻は日毎になってます。上記を踏まえると、八百屋の日毎の商品の仕入れデータかもと見当がつけられます。
しかし、実際のデータではデータの概要が伝えられても、カラム名が英字や数字で表現されているなどの理由からデータが何を意味しているのか理解できないケースもあります。その場合は、事前に関係者に説明してもらうことは大事です。
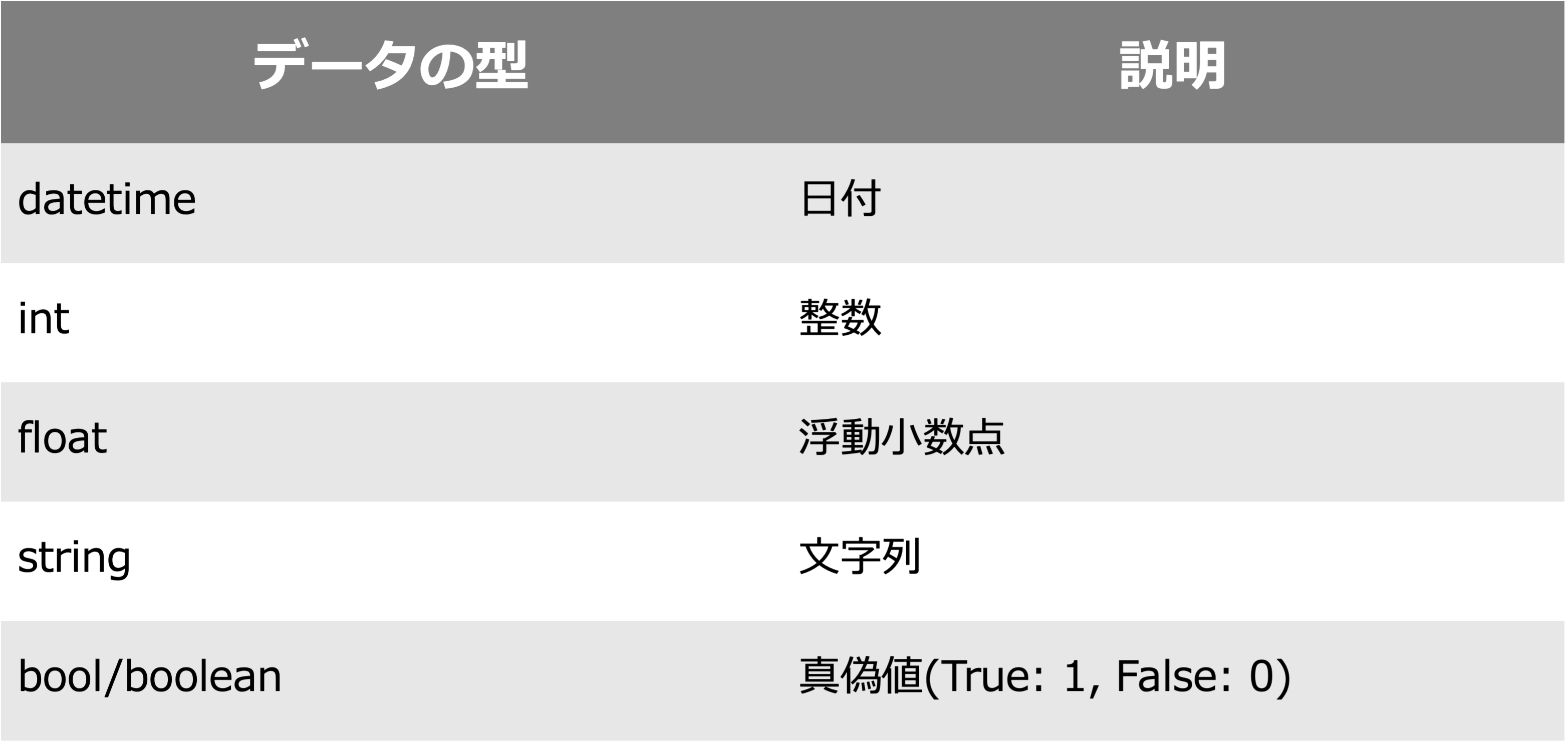
また、各カラムを見ると datetime、string、int などが記載されているかと思います。これは、各カラムのデータの型を表しております。分析者がプログラムを通じてコンピューターにデータを読み込ませ、分析の計算処理を任せる際に、データの型を宣言したり、変換するなどの操作は重要になってきます。代表的なデータの型について、以下に整理します。
分析するにあたって、文字列のままだと、数値計算のみを扱うモデルに適用できないなどの理由から整数または浮動小数点に変換するなどの前処理が必要になることもあります。そのため、データの型を確認し、必要に応じて前処理をしましょう。
Node-AI では、文字列置換やカスタム前処理でデータの型変換ができます。カスタム前処理カードは、代表的な前処理に関するコードをカスタムカードギャラリーで参考にしつつ、機能カードにはない前処理をカスタマイズし、実行できるカードです。実施したい分析に応じて、データの型はどうあるべきかを検討しましょう。
データの現状を把握しよう
これまで、データの大きさを把握し、変数の意味を確認することでデータセット全体の現状を把握してきました。最後に、データの詳細に関して現状を把握することの大切さについて記載します。
データを取り扱う際に、欠損値の有無は非常に重要なポイントです。欠損値が存在する場合、それがどの程度の影響を及ぼす可能性があるのかを予め確認しておく必要があります。以下では、欠損値について詳細に説明します。
欠損値について説明する前に、そもそも値が存在しないことをデータ分析においてどう表せばいいでしょうか? よく用いられるものには以下があります。
- NULL
- 該当するデータの箇所に、値が存在しないことを意味します。
- NaN(Not a Number)
- 該当するデータの箇所が、数値でないことを意味します
- NA(Not Available)
- 該当するデータの箇所が、何らかの理由で利用できないことを意味します。
お手持ちのデータを分析する際に、上記のような欠損値のデータがないかを確認しましょう。
欠損値の原因
データに欠損が発生する理由はいくつか考えられます。例えば、
- データの消失
- サーバダウンや IoT 機器の不具合によって、一部のデータが失われることがあります。
- 例: サーバがダウンしていた時間帯のデータが欠落している。
- 元から存在しない
- センサーや装置が特定の条件下でしか作動しないために、データが存在しない場合があります。
- 例: 人感センサーが人を認識しなかった時間帯のデータが無い。
これらの欠損を適切に処理しないと、分析結果に歪みが生じる可能性があります。
欠損値の補間
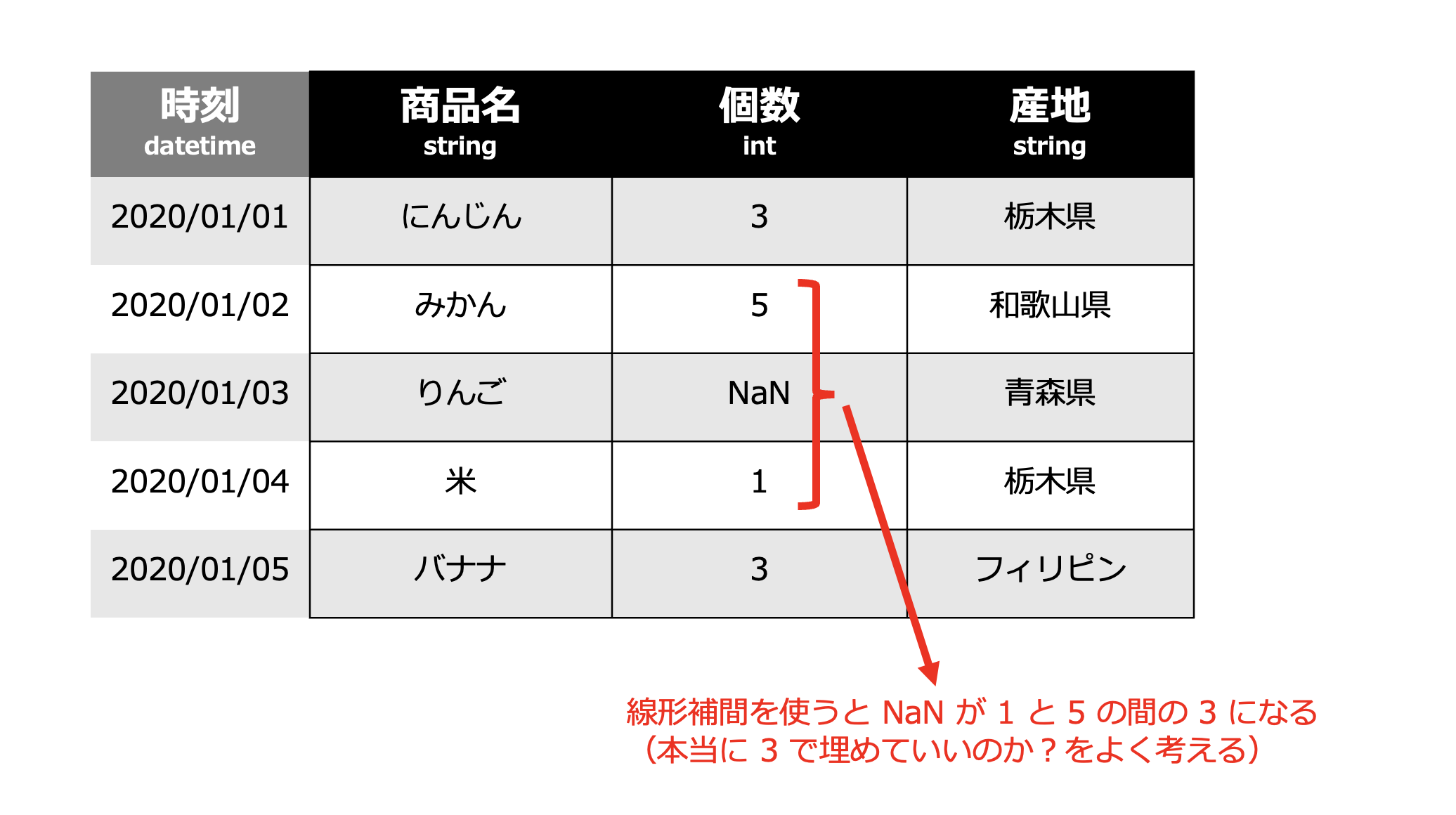
「補間(ほかん)」とは、間を埋めるという意味で、数値データにおいて欠損している部分を適切な方法で埋めることです。
代表的な補間方法としては線形補間があります。これは、前後の値の平均値を用いて値を補間するというものです(前後の値を直線で結ぶイメージです)。
Node-AI では、欠損値補間カードにより、線形補間などの代表的な補間方法を簡単に実装できます。
欠損データが持つ意味
欠損データの補間は、場合によっては「データの改変」に近い行為と見なされることがあります。そのため、補間の必要性を慎重に判断し、適切な方法を選択することが求められます。
特に気をつけるべき点として、欠損値そのものに意味がある場合があります。例えば、あるセンサーが特定の条件下で動作していないことが欠損データとして現れる場合、その欠損自体が貴重な情報を含んでいることがあります。
例えば、人感センサーが人を認識しなかった時間帯に欠損データが多い場合、その時間帯に人が少なかったという事実を示している可能性があります。
この場合、やみくもに線形補間を使うのではなく、別の値を使って補間をしたり、そもそも欠損値を含むレコードを学習で使わないようにしたりすることも検討すべきでしょう。Node-AI ではカスタムカードを使うことにより、このような処理も実現できます。
おわりに
データ分析において、データの全体像を正確に把握することは非常に重要です。本記事では、データの大きさ(レコード数とカラム数)、カラムごとのデータ種類、そして欠損値の有無とその取り扱いについて詳述しました。
データの大きさを把握することで、適切な計算リソースを予測し、適切な処理手法を選択できるようになります。カラムのデータ種類を理解することによって、適切な前処理や分析手法を選定できます。欠損値の取り扱いに関しては、適切な補間方法を選び、欠損が分析結果に及ぼす影響を最小限に抑えることが求められます。
データの品質を維持し、信頼性の高い分析結果を得るためには、これらのステップを慎重に行うことが不可欠です。適切な前処理を行うことで、その後の分析やモデルの性能が大きく向上し、より正確で有意義な知見を得ることができます。