
編集日
2024年6月
カテゴリ
前処理/可視化
データを手にしたあなたが精度の高い AI モデルを作ろうとすることは、用意された食材からおいしい料理を作ろうとすることに似ています。
ベテランシェフが食材の選定と下処理に時間をかけるのと同じように、熟練のデータサイエンティストはデータの収集と前処理に特に注意を払います。 この記事では、そんな重要なプロセスである前処理に着目し、Node-AI を使用しながら理解を深めていきましょう。
プロの真似から始めよう
未経験の料理を闇雲に作っても、うまくいく可能性は高くありません。
ここではカレーライスを例に、おいしく作る方法を考えてみましょう。
まず「カレーライス レシピ」などで検索すると、プロが試行錯誤して完成させた調理方法が見つかります。
なぜそのような切り方をするのか、調味料の量はどのように決めているのか、最初はよくわからないかもしれません。 でも、そのレシピをそのまま真似てみると、おいしいカレーライスができる確率はぐっと高くなります。
データサイエンティストも同じです。 最初は他のデータサイエンティストが作ったレシピ(分析コード)を真似て試していくことで、 基本的な技術が身についていきます。
理由がよくわからず機械的に行っていたことも、少しずつ感覚的に理解できるようになります。 いきなり全ての現象を理解しようとすると、いつまでも終わりが見えず、つまらなくなってしまいます。
ここから先の内容は、そのようなレシピの話と、その背後にある理由の話で構成されます。 あなたがデータ分析をまだ始めたばかりなら、まずはレシピの真似から始めてみてください。
この記事を読む前に
データの前処理とは、料理における食材の下処理に相当します。
その前に、おいしい料理とは何なのか、作るための工程、そして下処理の意味について最低限の知識が必要です。 データ分析におけるこれらの基礎をより理解したい方は、以下の記事を先に読むことをおすすめします。
全体像
以下の図が、この記事で作成していく最終的なレシピです。
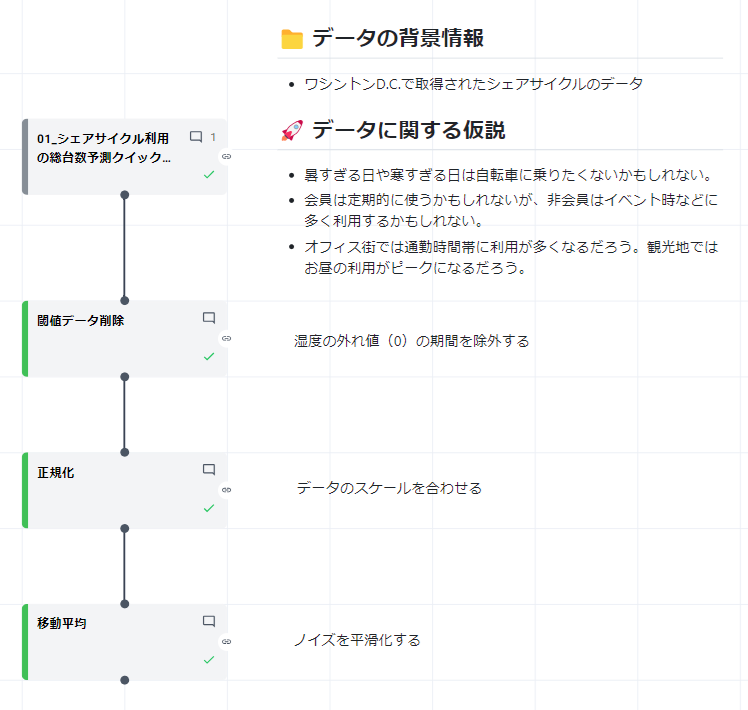
順番に、このレシピの内容について解説していきます。
データを観察する
データの前処理について考えるには、まずデータをよく観察することが重要です。これは料理で食材を見極めることに似ています。
データの形状や、常識とは異なる傾向などがないかを確認します。 しかし厄介なのは、現実のデータは非常に複雑であるということです。 人間が見ても気づかない異変が潜んでいたり、全てを把握できないほどデータ量が多いこともあります。
そのため、データの観察は 定性的な観察 と 定量的な観察 を組み合わせて行います。 データを見る角度を変えれば新たに見えてくるものもあるので、そのための可視化の手法もたくさんあります。
ただ、全て覚えるのは難しいので、ここでは基本的な観察から始めましょう。
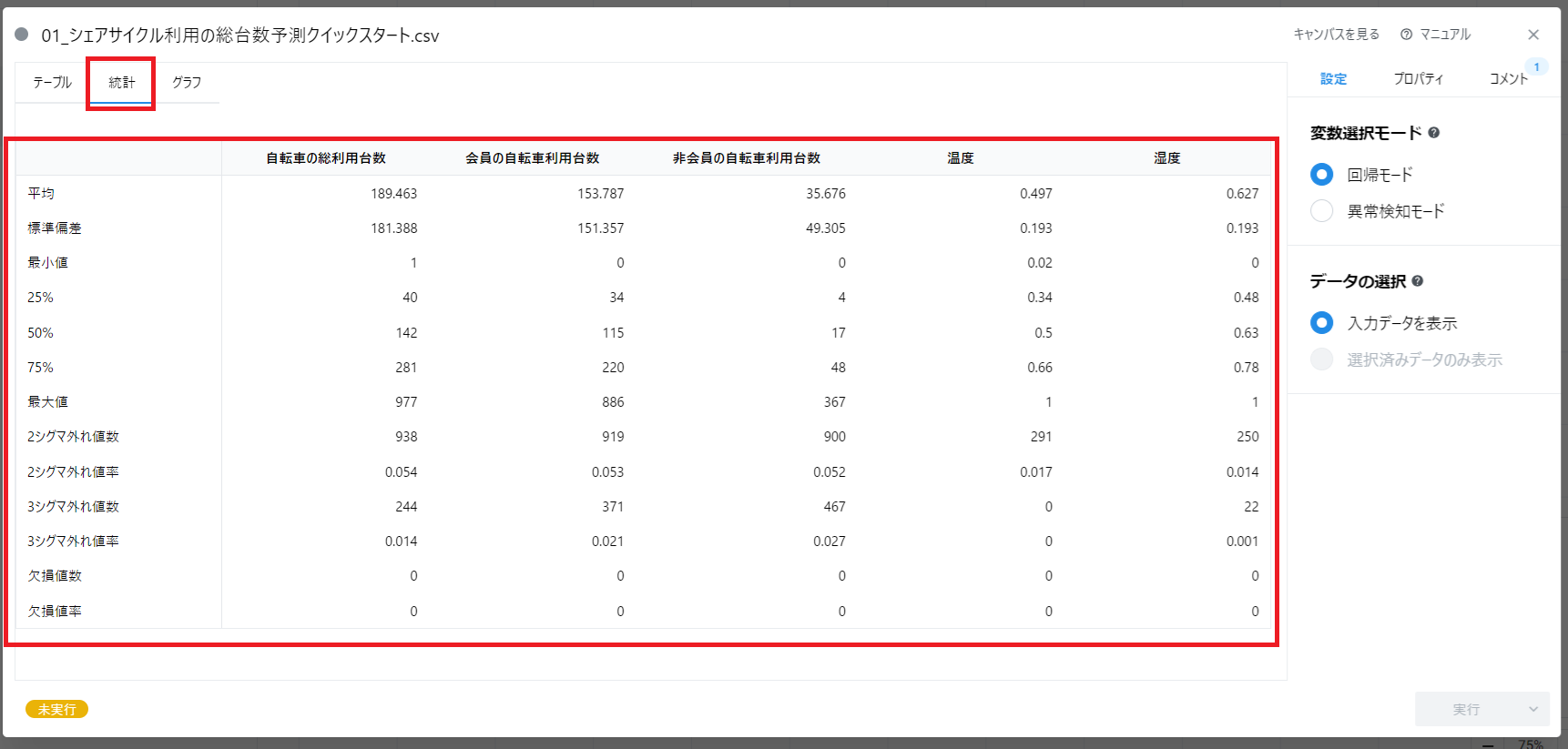
Node-AI において、アップロードしたデータをキャンバスに配置します。これを「データカード」と呼んでいます。 ここでは例として、公開データの 「シェアサイクル利用の総台数予測(クイックスタート用)」 を使用します。
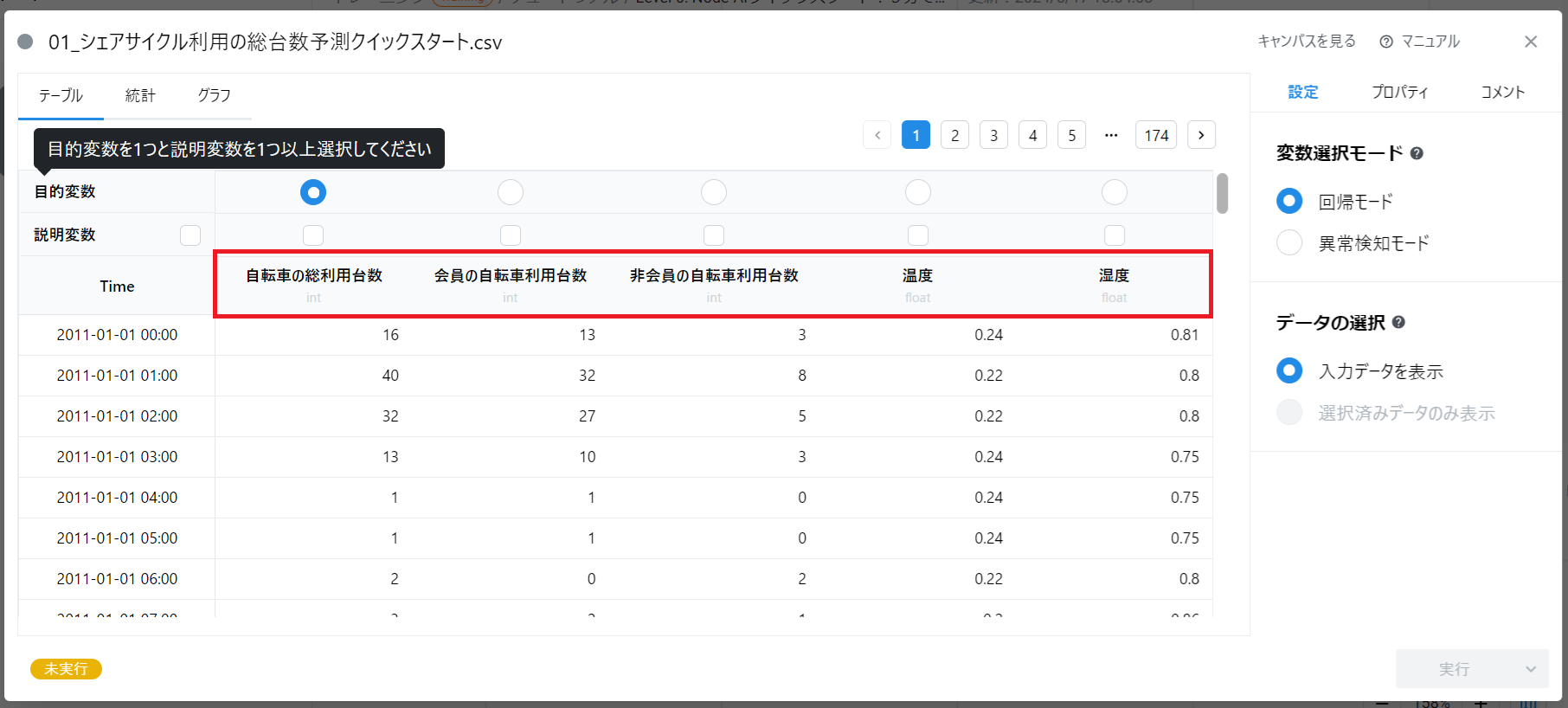
データカードを開くと、データに含まれる変数が表形式で表示されます。 このデータには以下の変数があるようです(画像の赤枠部分)。
- 「自転車の総利用台数」
- 「会員の自転車利用台数」
- 「非会員の自転車利用台数」
- 「温度」
- 「湿度」
この変数の情報だけからでも、さまざまな仮説を立てることができます。
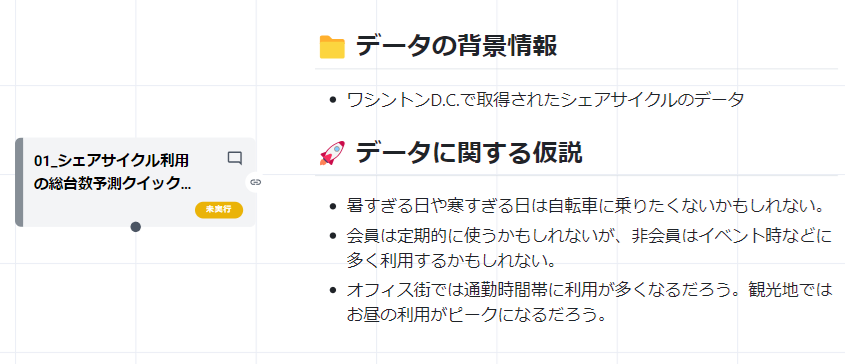
- 仮説の例1: 暑すぎる日や寒すぎる日は自転車に乗りたくないかもしれない。
- 仮説の例2: 会員は定期的に利用するかもしれないが、非会員は休日やイベント時に多く利用するかもしれない。
これはあくまで一般的な仮説です。 このデータに当てはまるかどうかはわかりませんが、こうした仮説を最初に考えるだけで、データの見え方がずいぶんと変わります。
さらに、次のようなより具体的な仮説を立てることで、それを検証するための追加の情報収集が必要なことにも気づくでしょう。
- 仮説の例3: オフィス街では通勤時間帯に利用が多く、観光地では昼間の利用がピークになるだろう。
なお、このデータはワシントン D.C.で取得されたシェアサイクルのデータです。 国や文化によってシェアサイクル事情は異なるでしょうから、そういった理解を深めることも必要となります。
データ分析において、データに関する背景情報や業界特有の知識等のことを ドメイン知識 といいます。 精度の高いモデルを作るにはドメイン知識の活用が不可欠です。 またドメイン知識は体系化されていなかったり、個人の経験や勘として蓄積されている場合もあります。
そのため、後から他の人が見た時に共通理解を持てるように、ドメイン知識も含めてテキストに書き出しておきましょう。
定性的な観察
それではまず、データを定性的に見ていくところから始めましょう。 「グラフ」タブをクリックしてください。
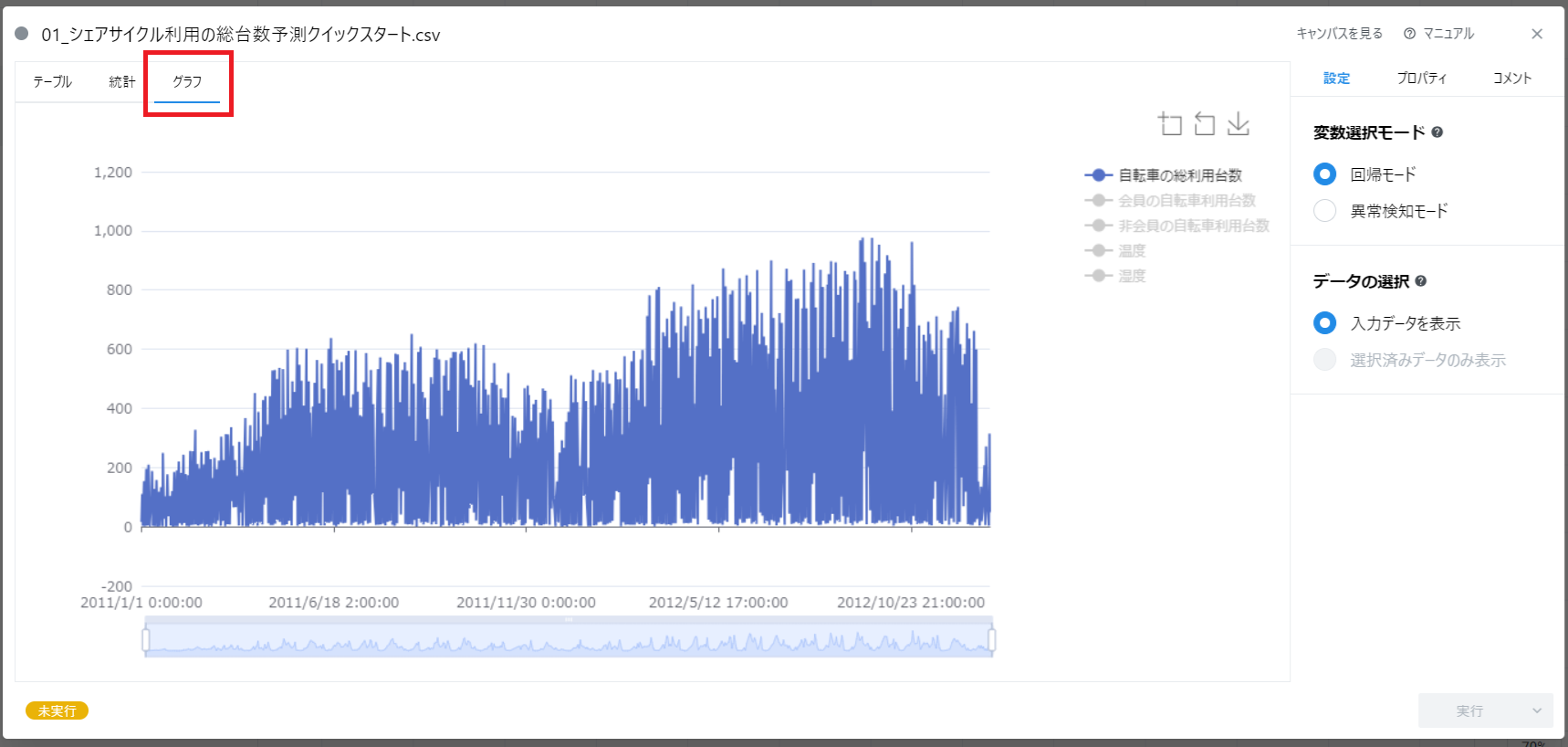
データの全体を見渡すと、値のおおよその範囲を直感的に理解できます。 途中で急に大きな値が現れたり、傾向が変わったりしていれば、それは気にかけておくべきことです。
この例のデータの「湿度」に着目すると、一部のデータが 0 となっていることに気づきます。
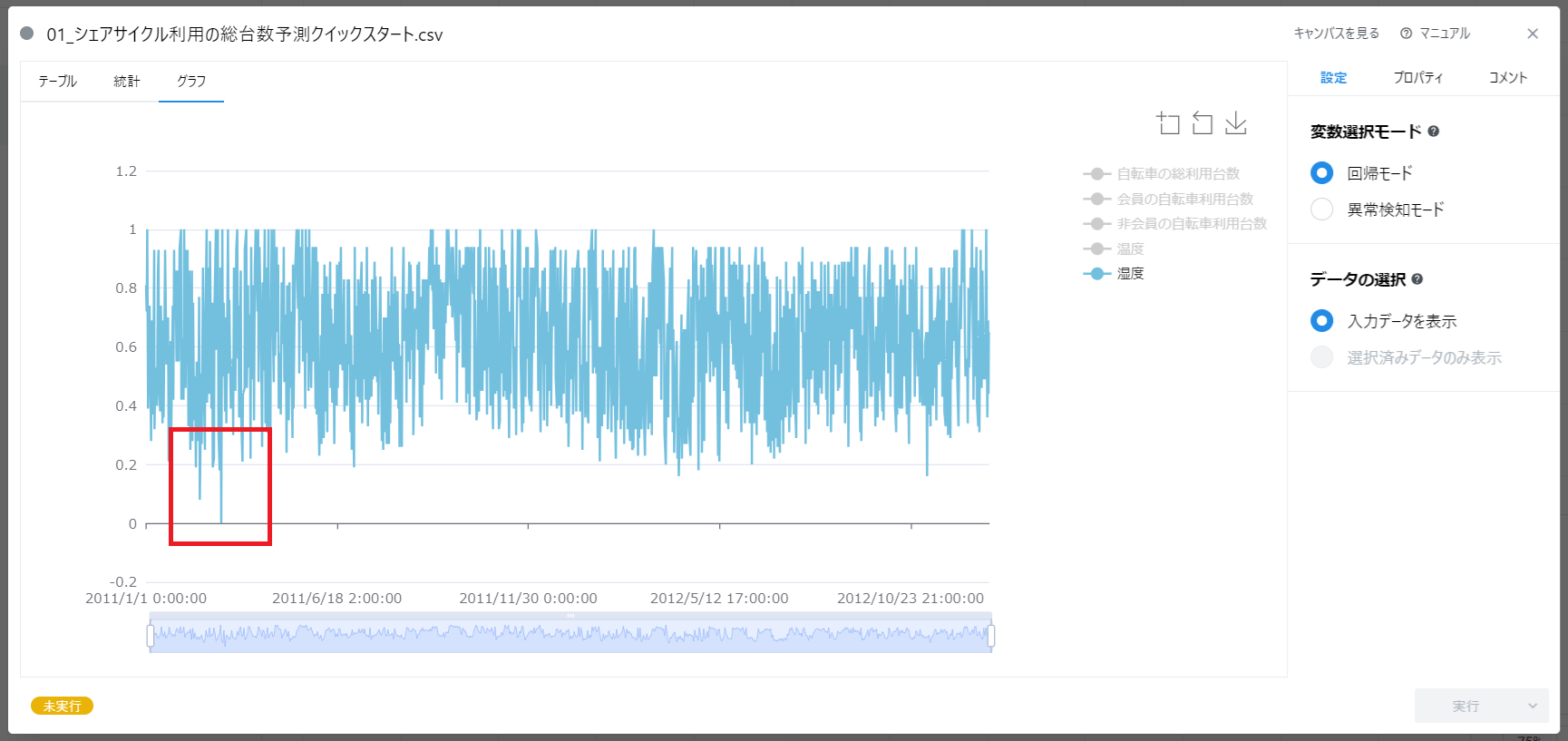
また、データを拡大して詳細をみると、より具体的なデータの形状がわかります。
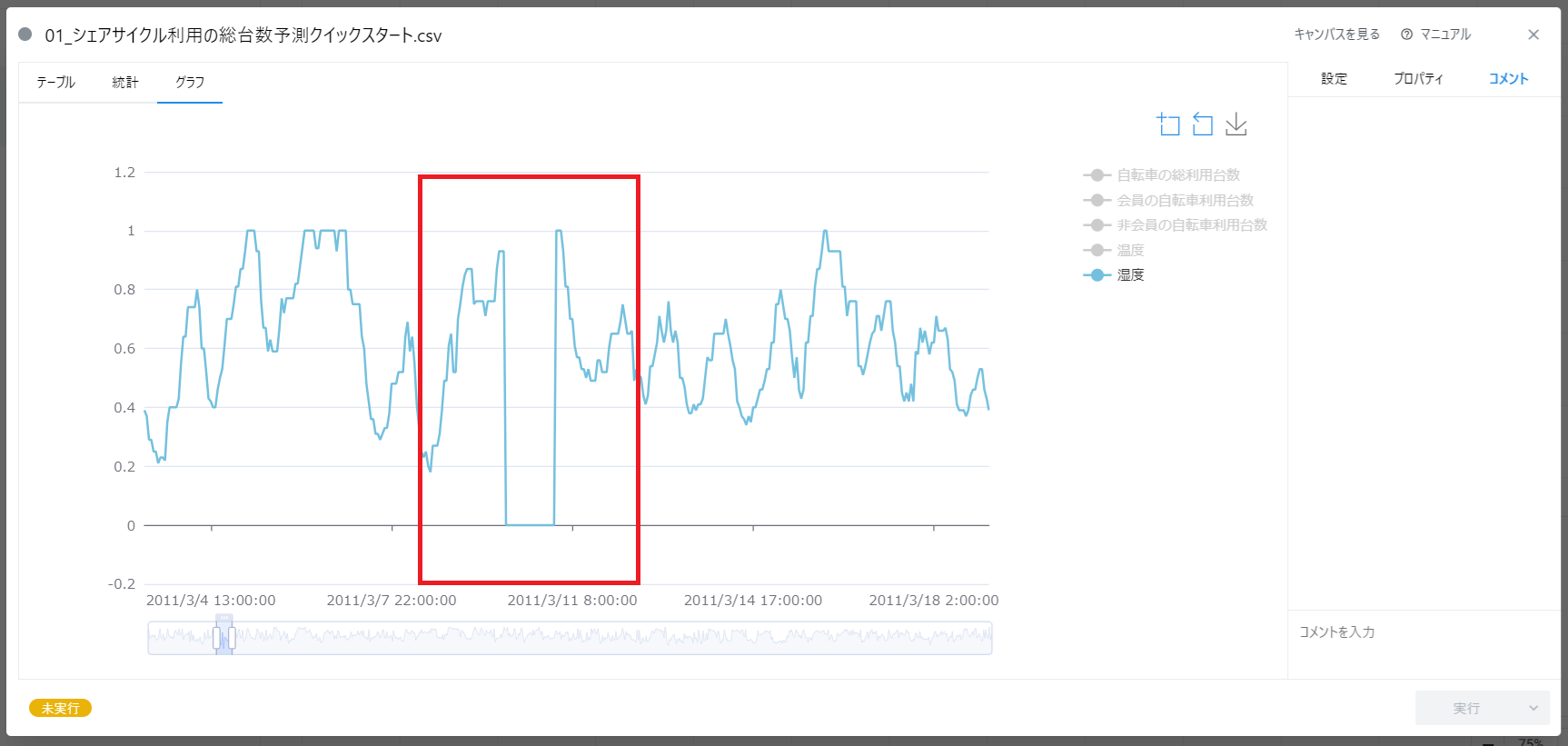
湿度のデータは 0~1 の範囲で変動していますが、着目した期間はごっそり値が抜けているように見えます。
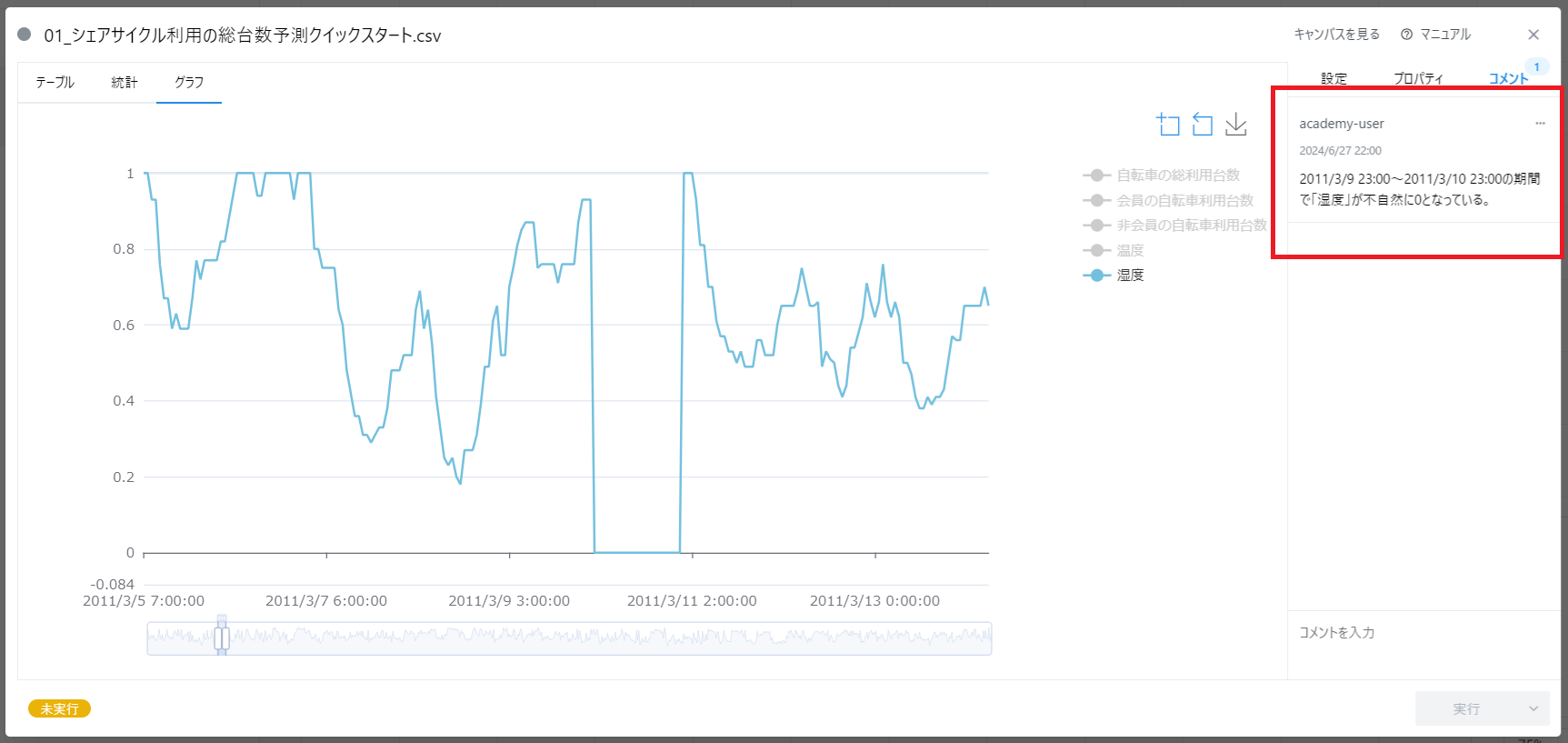
このように、データに関して気づいた点はコメントやテキストに残しておくとよいでしょう。 データ分析の道のりは長く、また試行錯誤が必要なものです。 得られた知見はその都度整理し、後から見ても思い出せるようにしておきましょう。
定量的な観察
定量的な観察方法の 1 つに、データの統計量を見る方法があります。
「統計」タブをクリックすると、データの変数ごとの統計量が一覧表示されます。これを使いましょう。
多くの専門的な用語が並んでいるので難しい印象を持つかもしれません。 ただこれらのうち大半は、単にデータの散らばり具合を数値化したものに過ぎません。
「平均」「最小値」「最大値」は一般的な用語ですから、最初に「25%」「50%」「75%」の説明をします。
四分位数
データを適当な小さい範囲で区切って数を積み上げたものを「ヒストグラム」といいます。 難しければ、単にデータの散らばり具合(分布)を可視化したものだと思えばよいでしょう。
※Node-AI では「ヒストグラムカード」で利用可能です。
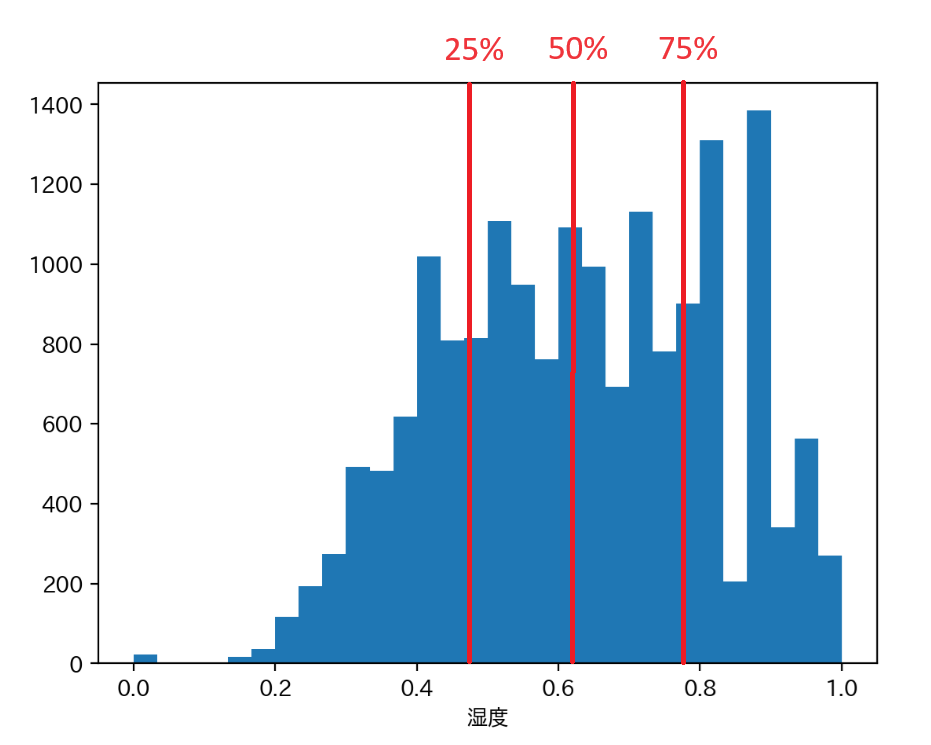
データを値が小さなものから順に数え上げた時に、データ全体の 25%の時点にあたる数値を「第一四分位数」と呼び、統計タブや図では「25%」と表記されています。 同様に 75%時点の数値(第三四分位数)を「75%」と表記しています。 なお、50%の時点の数値は中央値と呼び、平均値と一致するとは限りません。
このデータの「湿度」における 25%値は 0.48、75%値は 0.78 ですから、0~1 の範囲といっても、やや 1 寄りの数値が多いということがこれでわかります。
標準偏差と外れ値
「標準偏差」はデータの散らばり具合を示す指標で、一般にシグマ(σ)という記号で表されます。 数学的な解説はここではしませんが、正規分布と呼ばれる理想的なデータの分布において、 平均から 1σの範囲(平均-1σ~平均+1σ)に約 68%のデータが含まれます。 また 2σ、3σと範囲を広げると、それぞれ約 95%、約 99.7%のデータが含まれることになります。
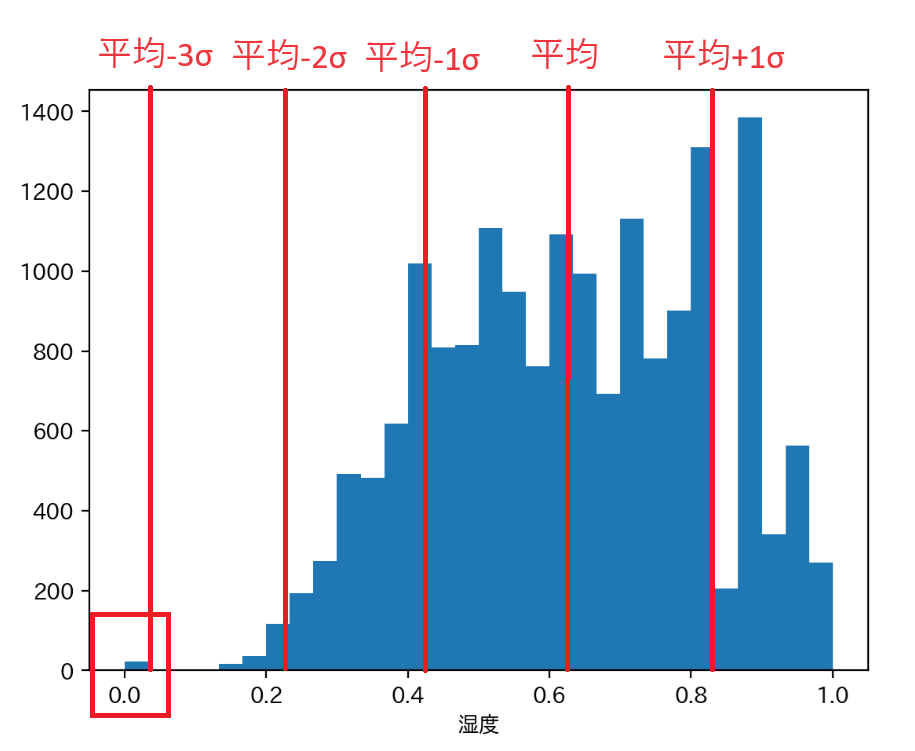
この割合はデータの分布の形状によっても異なりますが、 2σや 3σの範囲を取ると「ほとんどのデータがその範囲に含まれる」ことになり、 逆に考えると、 その範囲に含まれないデータは「非常にレアな値である」、つまり外れ値であると考える ことができます。
湿度データの場合は「3 シグマ外れ値数」を見ると 22 個で、全データ(17,379 個)の約 0.1%に相当することから、 実際にごくわずかなデータが外れ値と判定されています。
また、「平均 - 3σ」を計算すると 0.048 になることから「0」がこの外れ値の正体であると結論付けられます。
データに前処理を適用する
これまでの観察結果から、 「データの一部の期間で湿度に外れ値(0)がある」 ことがわかりました。
ここからは前処理を検討する段階です。
ただ注意すべき点は、外れ値自体が意味を持つこともあるということです。 例えば「特売セールをしたからバナナがいつもの 5 倍売れた」という現象は意味のある外れ値です。
今回の場合はどうでしょうか。単に湿度のデータが正常に取得されていなかったように見えます。
このような外れ値に対処する方法として、 「適切な値に補正」 したり、 「欠損値として処理」 することも考えられます。
実際のところ、どのような処理が正解かはモデルを作るまでわからないことが多いのですが、 今回は湿度の外れ値の期間が限られるため、 「該当期間のデータを除外」 することにしましょう。
※欠損値の処理方法については まずは、前処理を考えよう でも解説しています。
閾値データ削除カードの適用
Node-AI において「該当期間のデータを除外」するには、 閾値データ削除カード という前処理を適用します。
これはある変数に着目し、閾値(境界線)以上または以下の値であるレコードを除外する前処理です。
今回は「湿度が 0 以下のデータを除外する」と設定を行い実行します。
実行が完了したら、データが正しく除外されているのか確認しましょう。
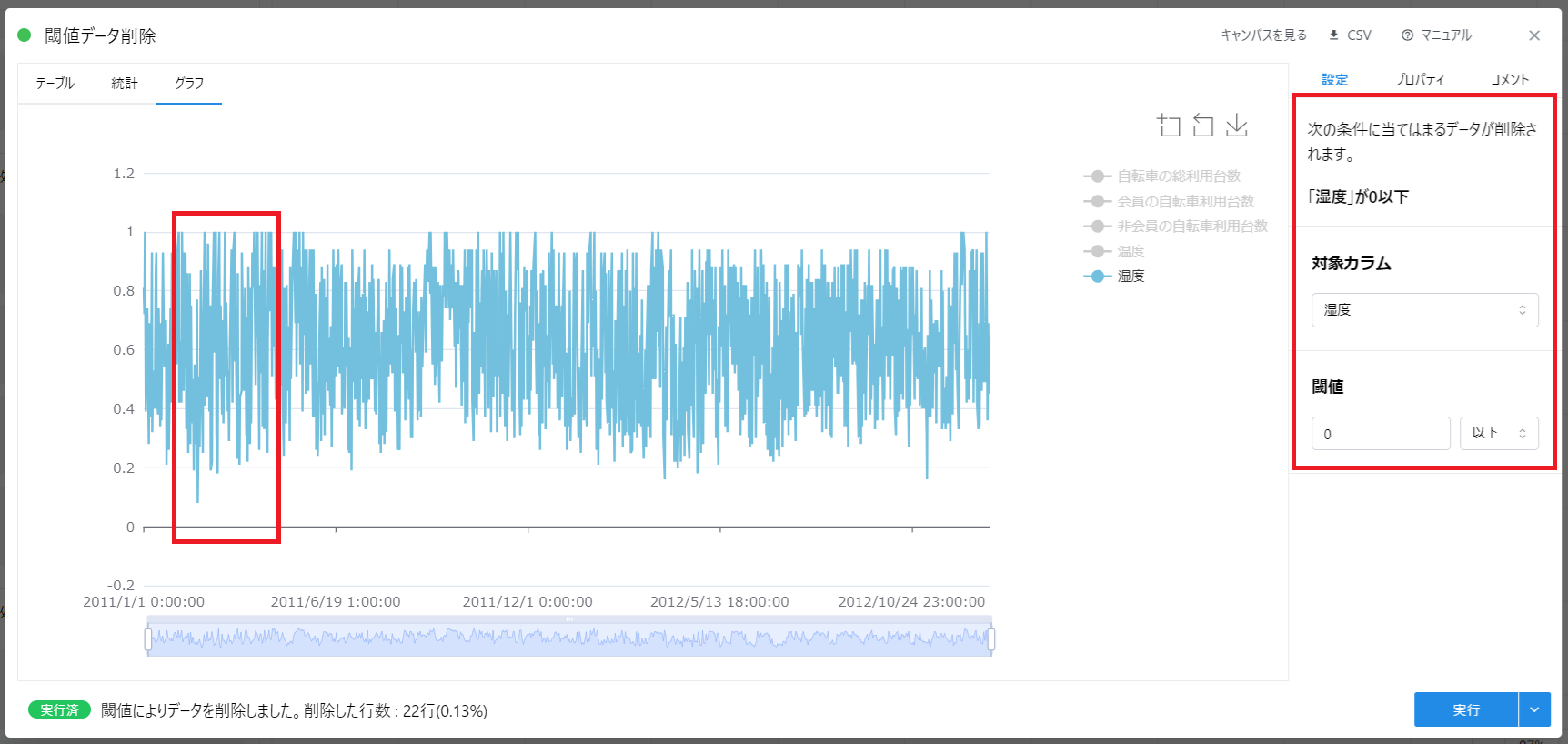
「グラフ」タブでは、先程見えていた湿度 0 の期間が見えなくなっています。
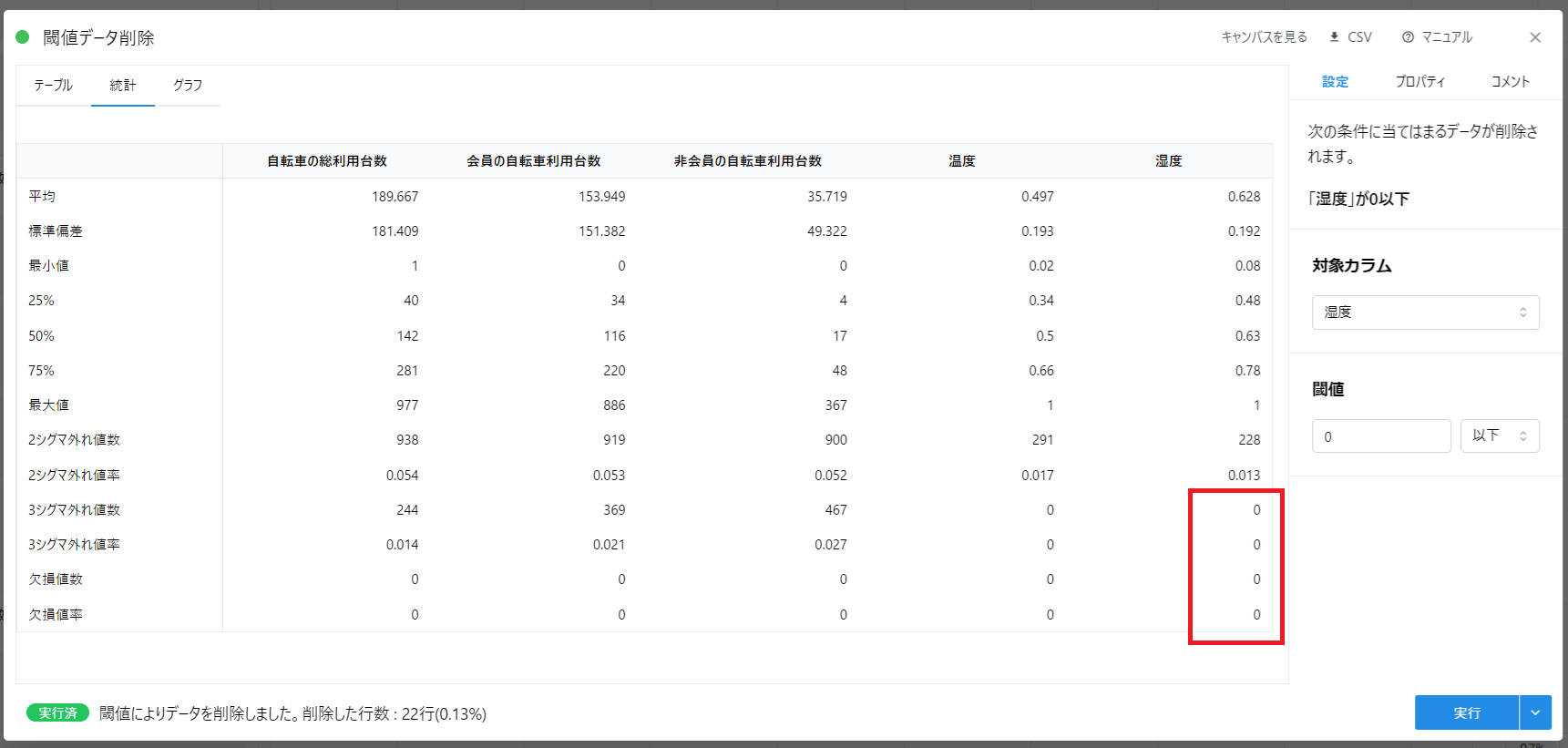
「統計」タブでも同様に、湿度の外れ値が 0 となっていることがわかります。
コラム: 外れ値を除外する理由
外れ値はなぜ AI モデルの精度向上にとって邪魔な存在なのでしょうか?
それは、AI モデルがデータを学習する仕組みに理由があります。
AI モデルは説明変数と目的変数がペアになったデータセットを大量に読み込むことで学習されます。 モデルはそのデータセットから何らかの特徴を見出し、パターンを抽出します。
もしデータセットに外れ値が含まれていると、 AI モデルは外れ値もそのままパターン化しようとします。 人間のように「あ、ここは湿度がなぜか取れてないから無視しよう」という発想は AI モデルには基本的にありません。
その結果、意味のない外れ値がパターン化され、AI モデルの予測が意図せず精度低下したり使い物にならなくなることがあります。
正規化カードの適用
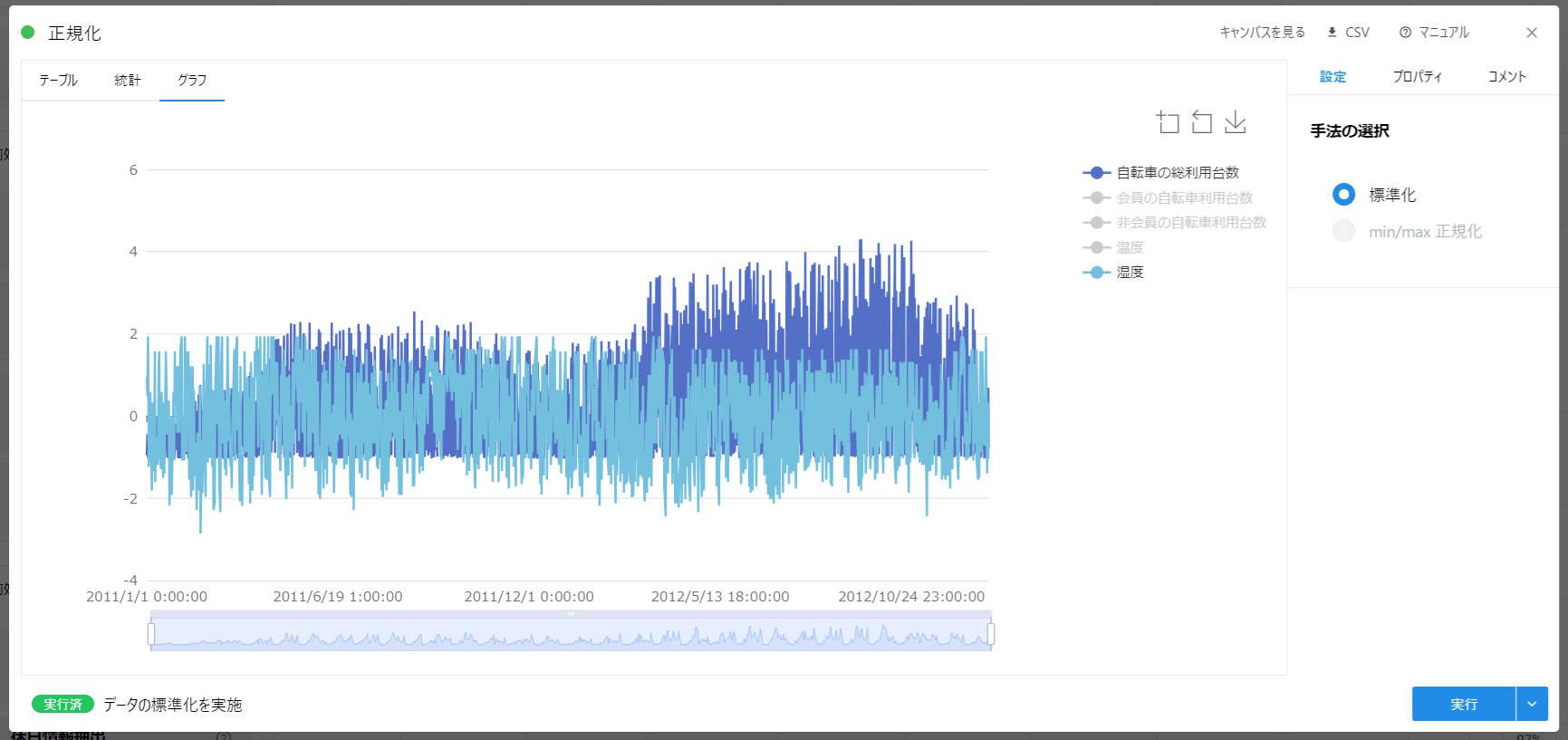
データをグラフで見た時に、「自転車の利用台数」と「湿度」を同時に表示するとどうでしょう。
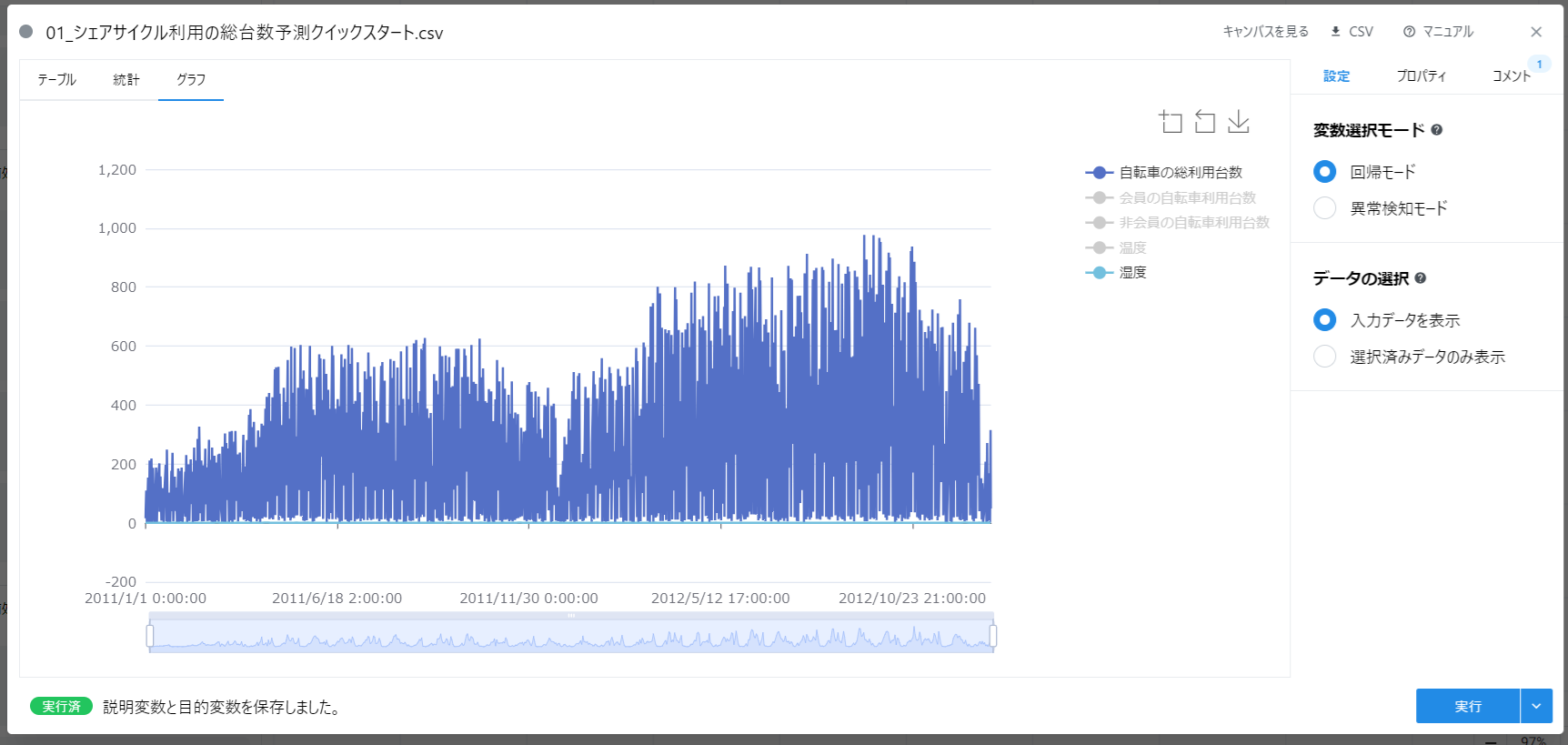
「湿度」は 0~1 の数値であるのに対し、「自転車の利用台数」は 0~1000 と、大きな範囲の値を取ることがわかります。 これでは同時にグラフに表示しても比較がしにくいことに加え、 AI モデルの精度低下や使い物にならなくなる可能性があります。
ここからは厳密ではない例え話になります。
カレーライスにはジャガイモとニンジンを入れますよね。 例えば、とても大きなジャガイモをそのまま入れ、小さく刻んだニンジンを入れて長時間煮込むとどうでしょうか。 ニンジンの形は崩れるか、または見えないほど溶けてしまいます。
AI モデルにもそれに近いことが起こります。 範囲が大きすぎる変数と、小さすぎる変数が混在すると、うまく学習できないことがあります。 この数学的な解説は他の文献に譲りますが、とにかく変数の大きさ(スケール)を揃える必要があるということです。
ただし最近は高機能な鍋も出てきたように、 AI モデルにおいても変数のスケールを気にしなくてもうまく学習してくれるものが登場しています。
特に Tree 系と呼ばれる AI モデルでは正規化は基本的に不要です。 Node-AI においては「決定木回帰」「LightGBM」がそれに該当します。
それ以外の AI モデルについては、基本的に正規化を適用するようにしましょう。
移動平均カードの適用
現実のデータは予想以上に汚れています。
ある分野では、このような汚れたデータは「キレイなデータ」と「ノイズデータ」に分離できるという考え方をします。
ノイズはデータの種類によって、さまざまな要因で発生します。 例えば健康診断等で心電図を計測する時に、「身体に力を入れないようにしてください」と言われることがあります。 これは、筋肉から発生する電気活動(筋電)が心電図にノイズとして影響し、見たいデータ(心電)が見にくくなるからです。
優れた AI モデルを作成するには、時にはこれらのノイズを取り除く必要があります。 そのための前処理は多く考案されていますが、Node-AI では「移動平均カード」が最初の選択肢になります。
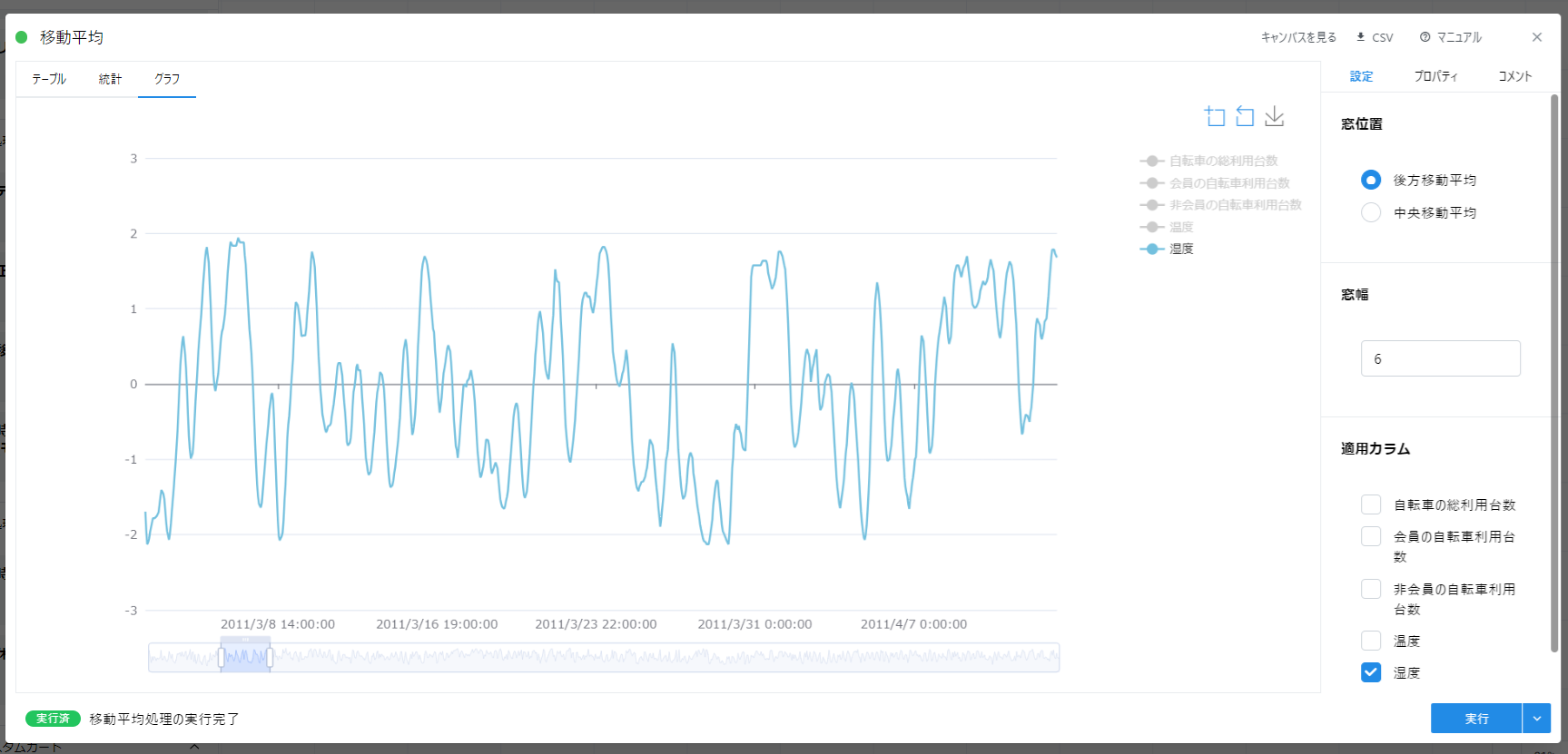
湿度のデータに移動平均を適用すると、データが滑らかな形状になることが確認できます。
今回の湿度データにノイズがどの程度混入しているかは明らかではありません。 ただ、グラフを拡大して確認すると、1 時間ごとに値が小さく変動している箇所が見られます。 この小さな変動は意味のある変動でしょうか? または何らかの誤差(機器の測定誤差など)によるものでしょうか?
意味のない変動であるなら、平滑化することでモデルの精度改善に役立つかもしれません。
ただ一方で、滑らかさの度合い(窓幅の設定値)を大きくするほど、元のデータの特徴も失われる可能性があります。 これは、お米も研げば研ぐほど甘みや旨味が失われることにも似ています。
滑らかさの調整は適切なバランスを見つけることが重要です。 そのため、ここでもドメイン知識が必要になることがあります。現場のプロはデータのどこに着目しているのでしょうか?
コラム: ノイズを除外する理由
ノイズを除外する理由は比較的直感的に理解できるでしょう。
人間が何かのデータのグラフを見る際、ノイズがあると元のデータの傾向が視覚的に捉えにくくなります。
心電図測定の例で考えてみます。 心電図の検査により明らかにしたいのは、不整脈と呼ばれる心電図の異常の有無です。 不整脈はその種類ごとに特定のパターンの心電を認めることで診断されます。 ここに突発的に強いノイズが混入すると、不整脈特有のパターンがかき消され、発見が難しくなります。
同様に、 AI モデルにとってノイズはデータのパターン化を妨げる要因です。
AI モデルが「たまたま生じたノイズ」を過剰にフィッティングしてしまうと、実際にモデルを運用すると予測精度が低下する場合もあります。 ノイズとはいつも同じように発生するものではなく、元のデータと関係なく生じるものだからです。
その他の前処理
前処理と聞くと地味な作業に思われがちですが、とても奥が深く、試行錯誤に時間がかかるプロセスです。
データサイエンティストが行う作業の 8 割が前処理に費やされるという説もあるほどです。
基本的なレシピのことが理解できたら、今度は隠し味やトッピングを試してみたくなりますよね? Node-AI では前処理が柔軟に行えるよう、オリジナルの前処理を定義できるカスタム前処理カードを用意しています。
また、カスタム前処理カードの設定を簡単に行えるよう、カスタムカードギャラリーから処理をコピーして利用することも可能です。
あなたのデータに適切な前処理が見つかるかもしれません。
おわりに
今回は一歩進んだ前処理の考え方や手法について説明しました。
どのような前処理を試せばよいのかは、ある程度データを見るだけでも方針が立てられます。 まずは今回紹介した観点(外れ値、正規化、ノイズ)から確認し、手元のデータでお試しいただければと思います。